千帆杯”第2期TOP7思路分享
大模型开发/技术交流
- 千帆杯挑战赛
- LoRA
- SFT
3月22日834看过
PS:给自己打个广告,最近想做个文档格式转化的multi-Agent工具,分三期开发,现在处于第一期技术预研阶段

希望招募1-2个队友一起完善思路完善项目(希望对方是了解/熟悉开源模型微调训练的友友,因为这方面我是短板)。欢迎感兴趣的小伙伴加我V:1831216561 或者邮件a738531582@gmail.com
现在复盘了一下,和冠军的差距,主要还是对赛题评分规则和理解把握有偏差。自己理解的贺岁模型是生成或者回答任意类型的回答,但是没有想到会是完全是样例数据集类型的提问。所以当时模型评分的方向是往通用能力较强的方向走,而冠军是仅仅局限于五种提问,往过拟合的方向走。其次在数据集生成的训练数据上,怀疑用百度的ERNIE-Bot 4.0生成的数据,会比GPT-4这类其它的数据更符合ERNIE-speed和评分模型的偏好。
-
测试指标选定
根据比赛规则,大家需要经过第一轮的自动评估,因此第一步需要提高自动评分。
根据平台方案,测试指标分两种,自动规则和模型评分,自动规则主要由BLEU-4、ROUGE-1、ROUGE-2、ROUGE-L四个指标选定,这四个指标都是通过计算生成文本和参考文本之间的重叠度(如单词或短语的出现频率和顺序)来工作,从而提供一个量化的方式来评估机器生成文本的质量。但是对于创作类任务来说,存在着可能完全不一致但是接近满分的回答。如:
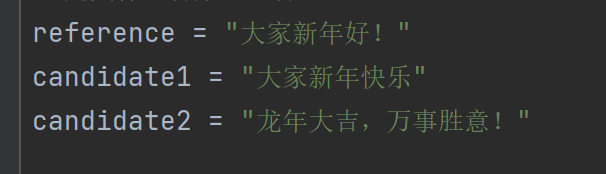
从上面的指标可以看出,对于创作类任务,自动规则是极有可能失灵的,因此基于此选定模型的自动评估作为自动判定的方法。
-
测试集制作
参考官方示例,使用GPT4制作了标注精准字数的问题集,只有11条,涵盖祝福语写作、文章写作、策划书、总结4个方面,确保完全不属于训练集


-
测试评估报告观察(默认评分模板)
3.1摸底基座模型能力
使用10分制的评分规则,对于测试集,基座模型评分约8.36,自己训练的约8.18-8.42。
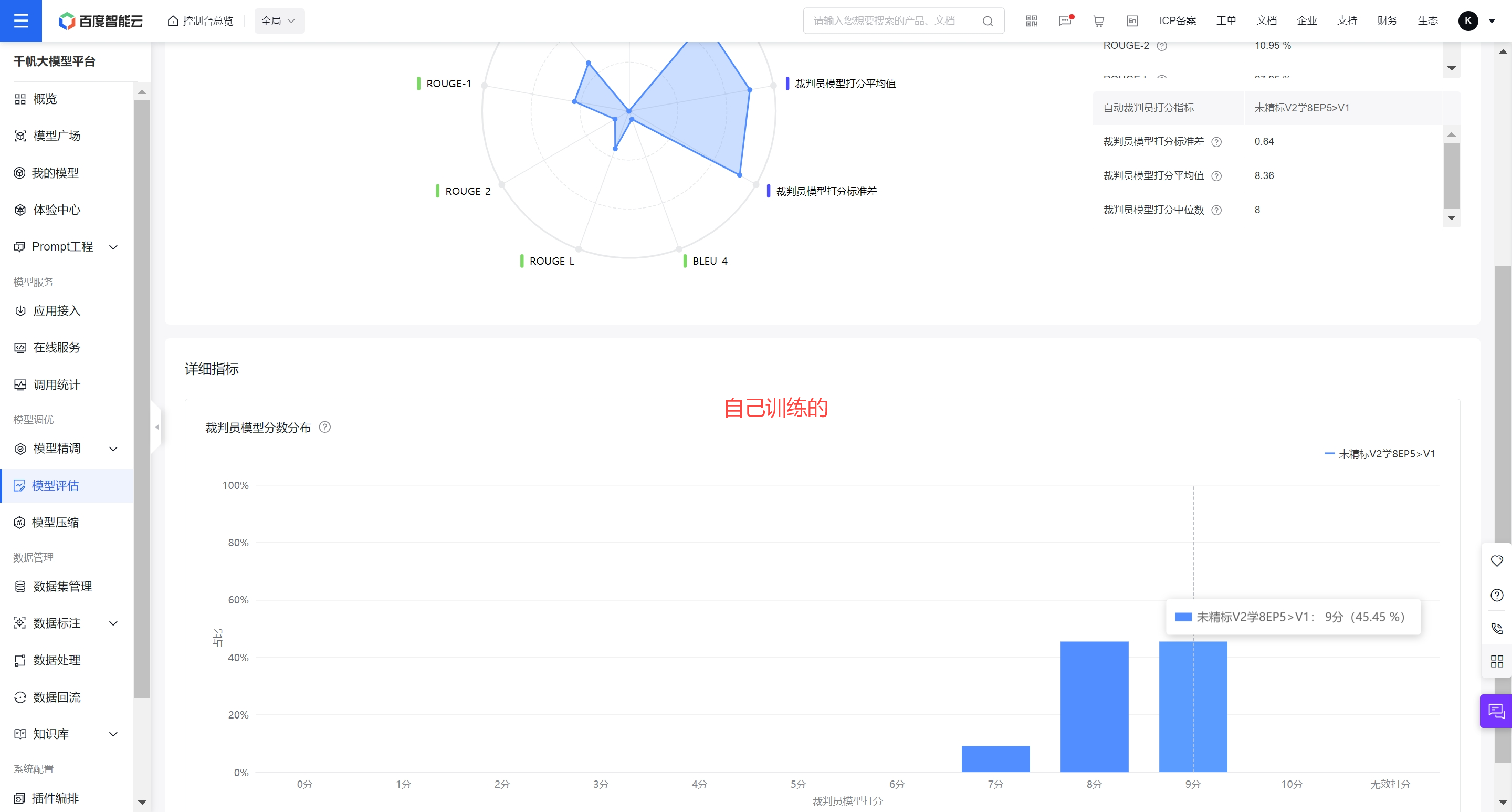
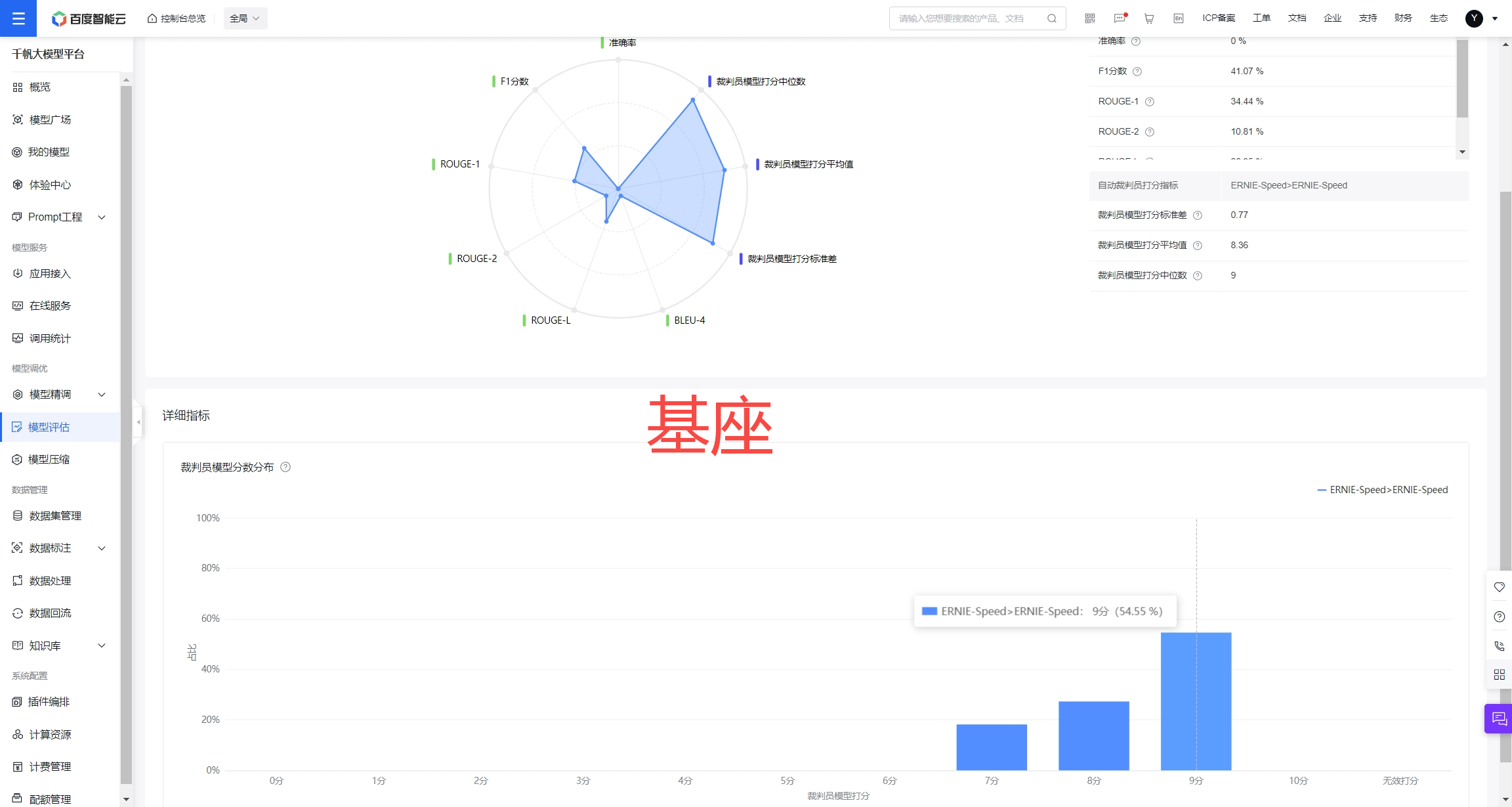
3.2对比测试集模型评估结果挑选最终模型
获取测试集评分到评估结果后,检查三点:
-
模型打分平均值、标准差(0.7以下基本上不会出现复现分值变化,过大的标准差会导致结果不稳定)
-
分值分布,恪守2个守则:a.不允许存在低分6分以下,说明存在能力缺陷。b.9分的分值比例,比例越高,可能比8分的质量不一定好,但是一定是符合评分模型喜好(实际上绝大多数情况确实就是好,9分分值越高,说明推理能力越强)
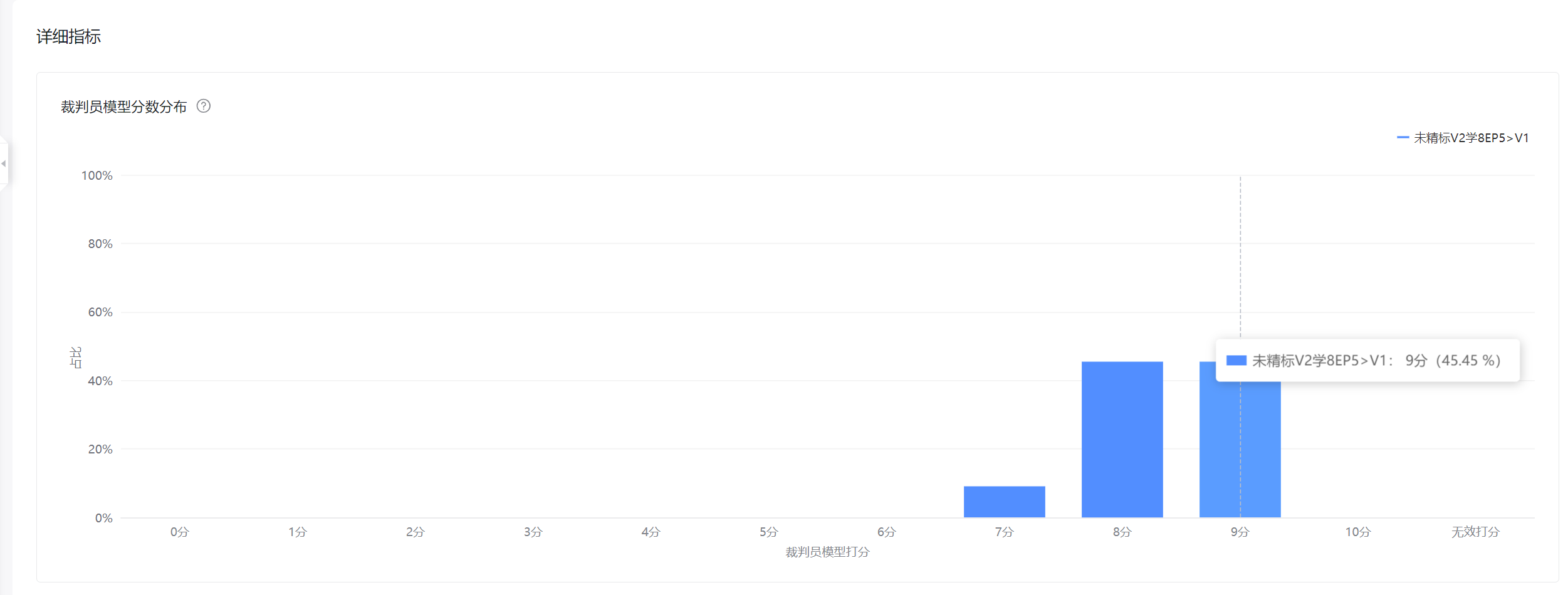
3.3模型评估详情对比
-
-
观察模型评分理由,发现9分实际就是满分,此外存在对比参考答案踩点给分的特点。基于第一章的测试指标原理说明,可知可能存在关键词不完全一致但是满分的回答,这种情况下模型呈现出细节对比的特点,谁的细节点体现的多,谁的评分高,这样反而导致了字数完全满足要求的答案并不得高分,反而是稍微偏多一些的更占优势。(字数多内容满分的回答约8分,字数少内容必定不会满分约7分,存在1分的差距),考虑到自动评估阶段字数打分不严谨,且以内容质量为主,因此优先内容,长度控制放其次。
-
-
仔细观察生成的文本质量,对于有的带有角色的创作,有的训练不对,角色的对象语气完全错误,如下图是正确的回答,错误的回答可能是用自然爱好者的角色对志愿者聊天。因此坚决拒绝该类型的数据集。
-
对于小作文类型的回答,坚决拒绝低分类的模型,这个对模型的通用推理创作能力要求更强,坚决避免低分回答。但是要接受部分答案分值偏低,因为可能存在多种因素,比如答案太优秀或者细节太多等,所以该部分需要使用人工评分对比。比如下面的,可能7分与8分差距不大,但是明显可以看出8分的更活泼流畅,结尾最终回扣主题,可以看出8分的作文模型比7分的更接近人类的思维。
-
-
超参调试
4.1确定Lora训练路线
超参部分走了很多很多很多的弯路,主要是由于第一次训练,参考SFT训练文档,使用lora和全量训练对比,一开始把训练集作为测试集,导致训练出了很多过拟合的模型。后面更换测试集后,发现全量训练极易过拟合,通用模型推理能力下降厉害,导致较低。
由于所有参数作用不确定,因此决定使用最笨的方法,控制变量一个一个测试。如下图,发现Lora极易取得高分,而全量训练普遍偏低(当时按照文档,epoch轮次都是设定的很高,而且追求Loss精度到小数点后三位)。
并且后续在字数长度控制中对比,再次发现全量训练的字数长度控制的特别差(在测试点全量字数精度只能正负40,而lora对于字数控制轻易达到了正负20附近,而且没有提升潜力),因此决定完全放弃全量路线。
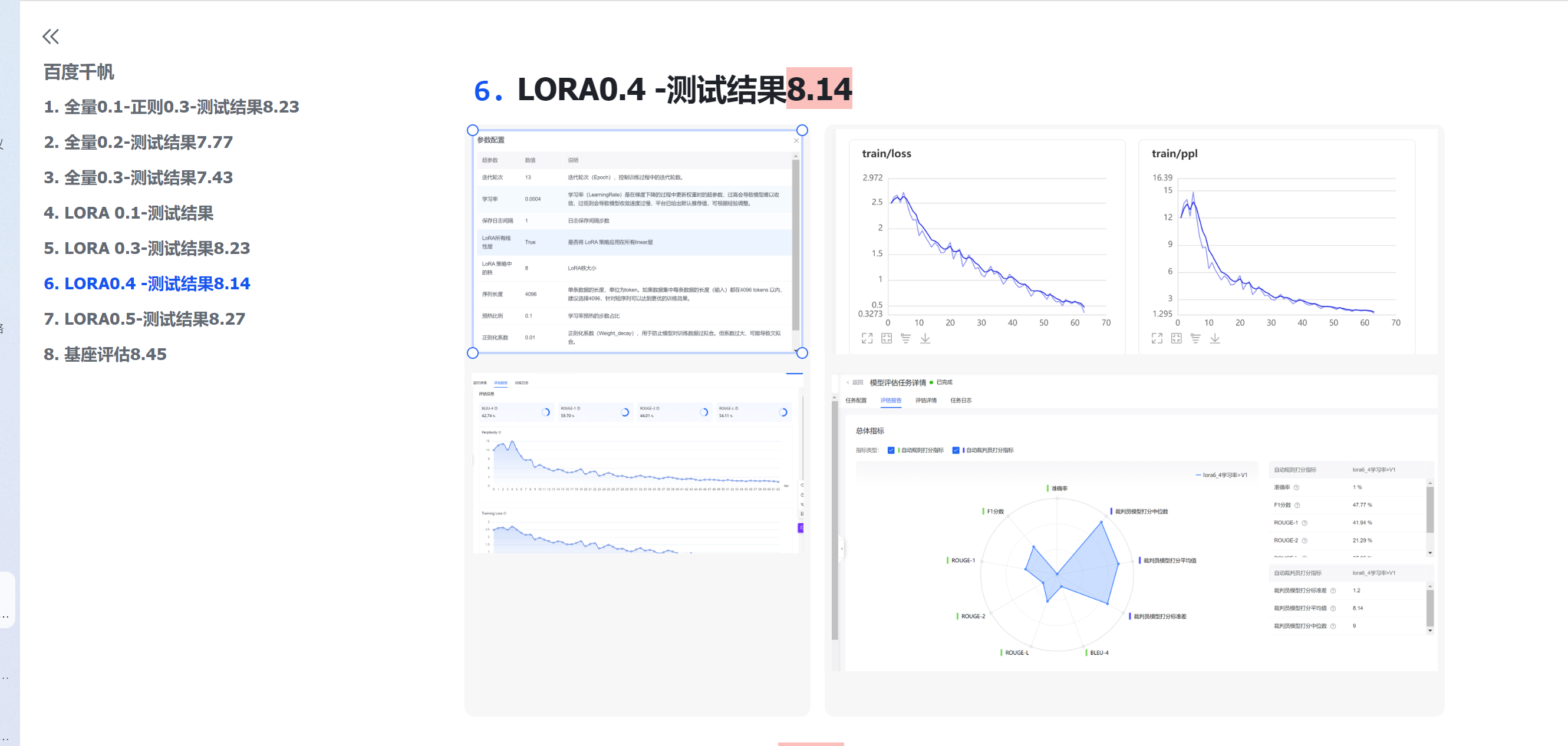
4.2确定正则系数
控制变量训练后发现正则系数大的数据生成更多样,调整到最大也不会不收敛,而且有存在各种表情输出更丰富的效果:比如会在社交媒体的场景生成笑脸😀等,但是由于对字数控制无作用。加之是隐藏参数,因此放弃对该参数进行调整。
4.3确定Epoch和学习率大致范围和作用
后续偶然发现lora训练中,epoch5和3与epcoh10的测试结果数据一致,意识到官方文档可能不太对。与此同时刚好官方回复邮件推荐EP3和5.因此修改成epoch3和epoch5进行训练对比。学习率确定了大于0.0003
4.4最终参数

训练集分割为1%
-
字数长度控制
5.1确定字符统计基准
确定excel函数中len函数不含空格和\n的字数长度就是word的字数,以此为基准,使用脚本批量修改数据集的prompt,如把不超过XX字的长度统一修改为精确字数的长度(例:生成不超过77字的祝福语)
5.2生成字符长度测试集
字数控制本来是基座模型的能力,一开始发现每次生成长度都不一样,无法正常评价,后续发现把温度和多样化参数调到最低,生成长度稳定,因此基于该基础挑选一个场景作为测试点。然后设计步长为5的测试集(生成5个字的春节场景、生成10个字的春节场景、生成15个字的春节场景...生成700字的春节场景),通过API调用方式批量生成,然后与基准长度对比(5、10、15。。。700)
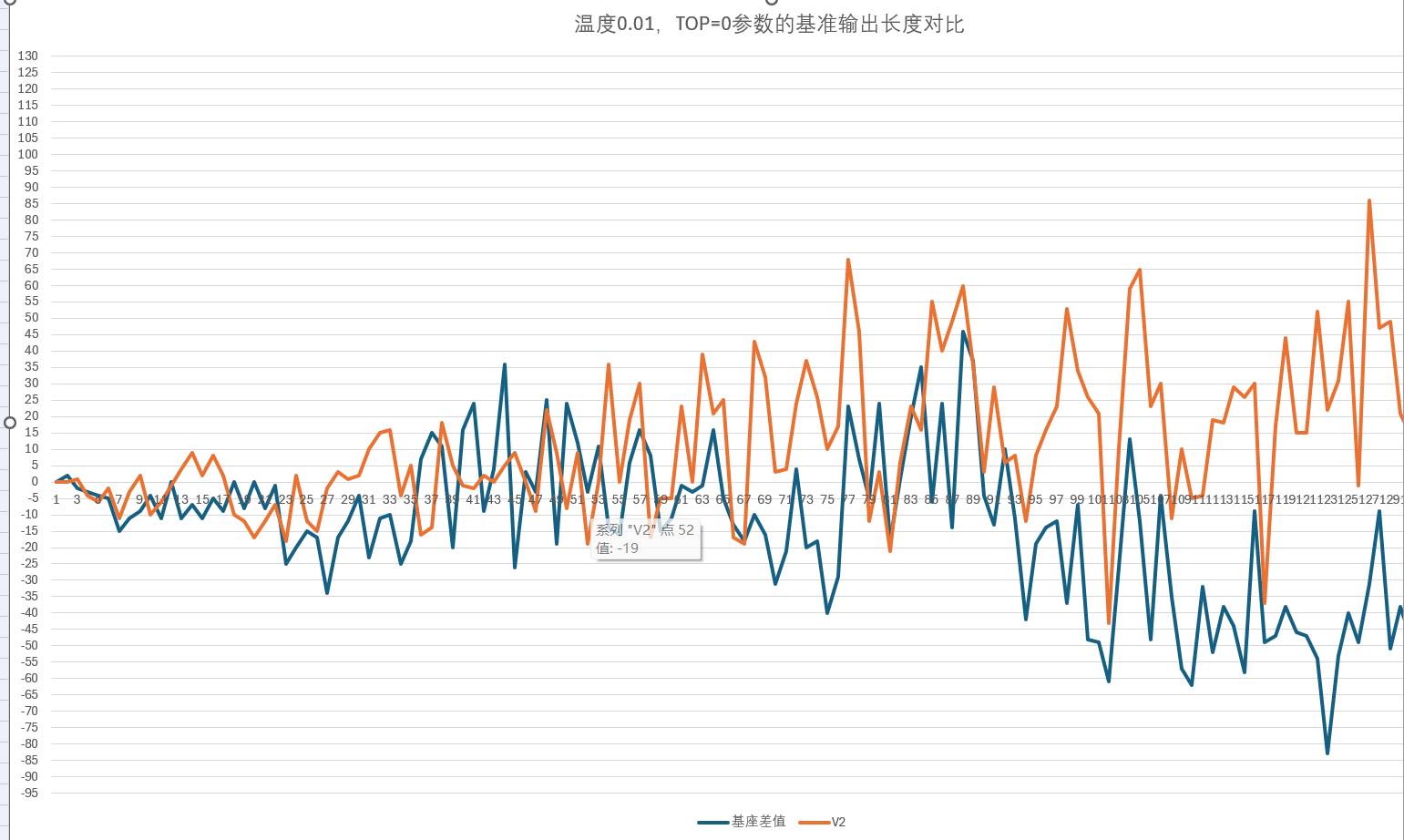
5.3符长度基准对比
从下图可以看出自己训练的模型(V2)对比基座模型的输出字数长度,在前面的250字会偏好一些,基本控制在15字内(X轴数值*5等于基准的字数)。在超过250字的后半段,相对于基准长度来说会偏少。说明对于长度输出是有起到一定的控制作用,但是如果通过调整top和温度参数(top=0.9,TEM=0.99),该曲线会居中一些。
-
数据集制作
观察官方的数据集,发现数据集很不错,基本无法通过AI诱导出这种水平的作文,可能是人工参与的,所以以其为基础训练集,在其基础上扩展。
6.1数据集及超参评价
本步骤确定所有训练方式的潜力,因此建立了表格。对于全量训练和Lora训练,从模型评分和字数控制两个角度对比评价
-
模型评分
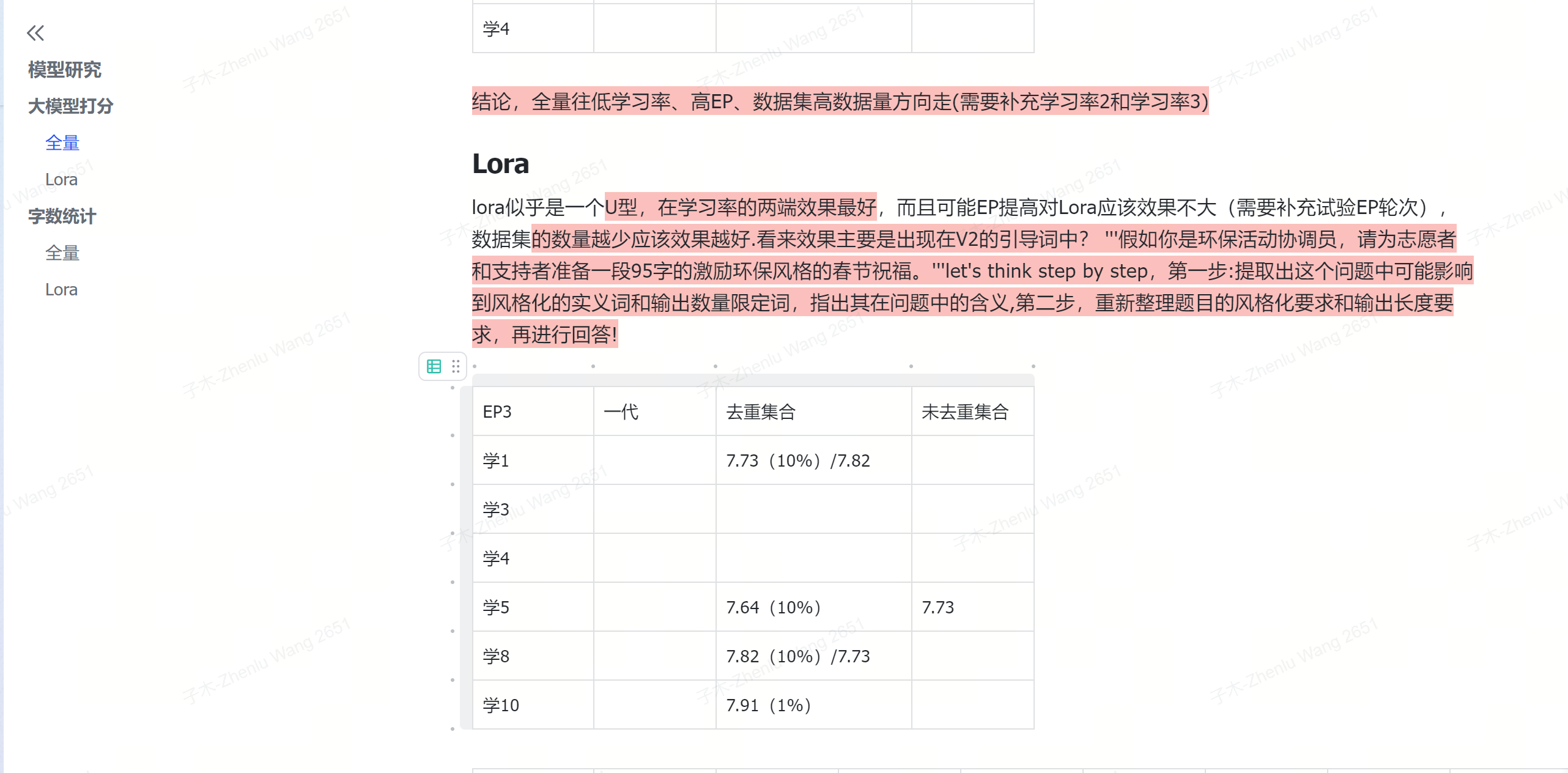
对于模型评分来说,全量需要往低学习率、高EP、数据集高数据量方向走。
lora似乎是一个U型,在学习率的两端效果最好,而且可能EP提高对Lora应该效果不大,数据集的数量越少应该效果越好.而且对比不同的训练模型,发现prompt中添加引导词有更强的效果,以及降低标准差的作用(此处存疑,有测试过其它构造的数据集,无该作用)。但是从测试数据中看来效果主要是出现在V2的prompt引导词中 :'''假如你是环保活动协调员,请为志愿者和支持者准备一段95字的激励环保风格的春节祝福。'''let's think step by step,第一步:提取出这个问题中可能影响到风格化的实义词和输出数量限定词,指出其在问题中的含义,第二步,重新整理题目的风格化要求和输出长度要求,再进行回答!
-
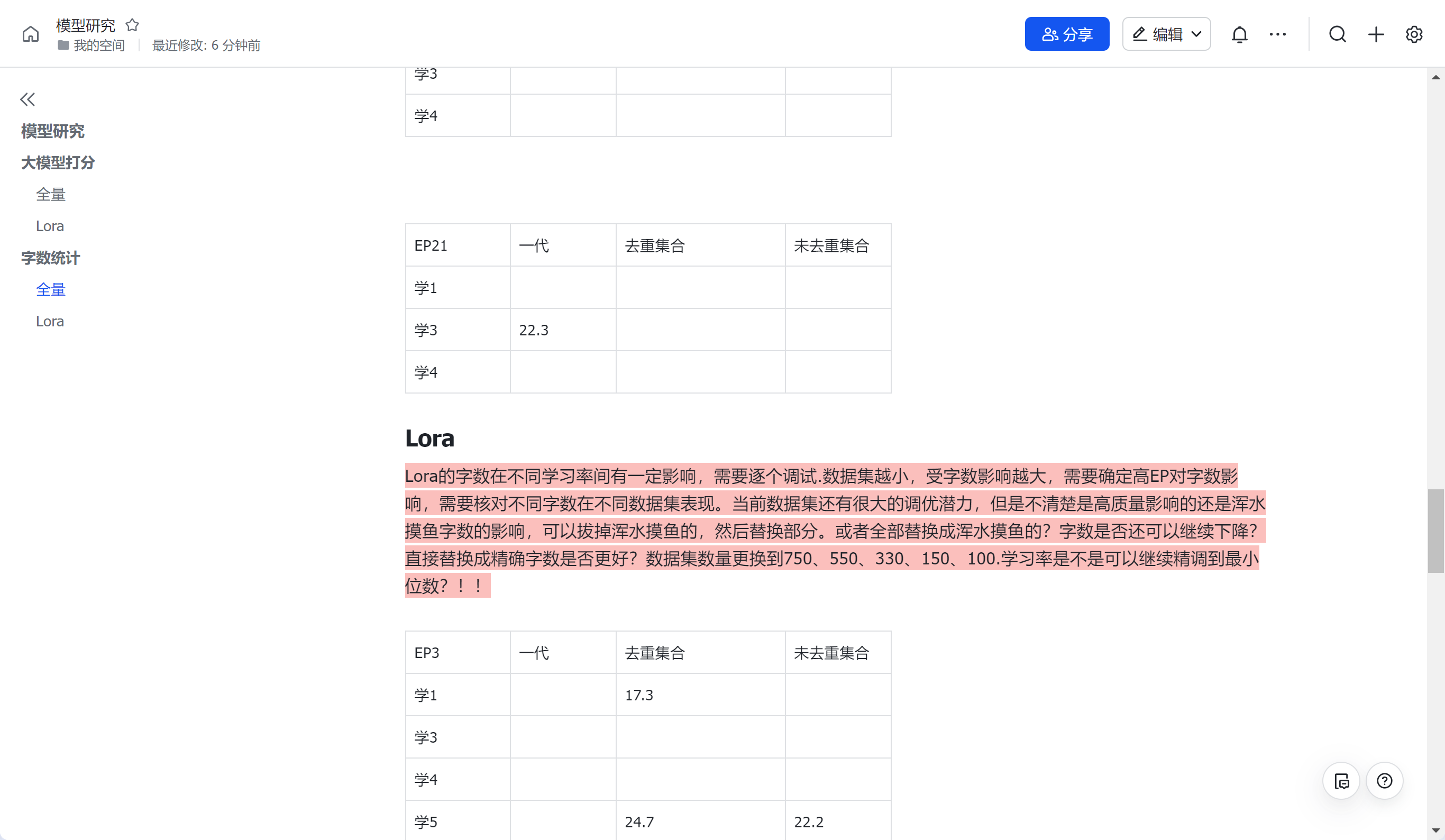
字数控制
全量的字数控制能力明显差于Lora,在EP5处,字数差值甚至能达到100多,直到EP提升到15,才能压缩到20左右,成本巨大,而且模型评分不佳。而对于Lora,发现Lora的字数在不同学习率间有一定影响,对比学习率1、3、、5、7、8、9、10后需要逐个调试.发现对于本人的数据集,学率设置为0.0008为最佳。并且数据集越小,受字数影响越大,提高高EP对字数控制和模型评分均无影响。基本上意味着lora训练的潜力也就在这里了,无法存在所有的长度都能达到5个字的精度
-
异常控制
经过lora训练的数据集,无法100%实现异常控制,与不添加异常的数据集差异不大,换种问法就不行了,因此训练集没有设置异常控制
-
训练集构成
-
训练集主要构成如下:
-
56条官方示例
-
72条的字数长度输出示例
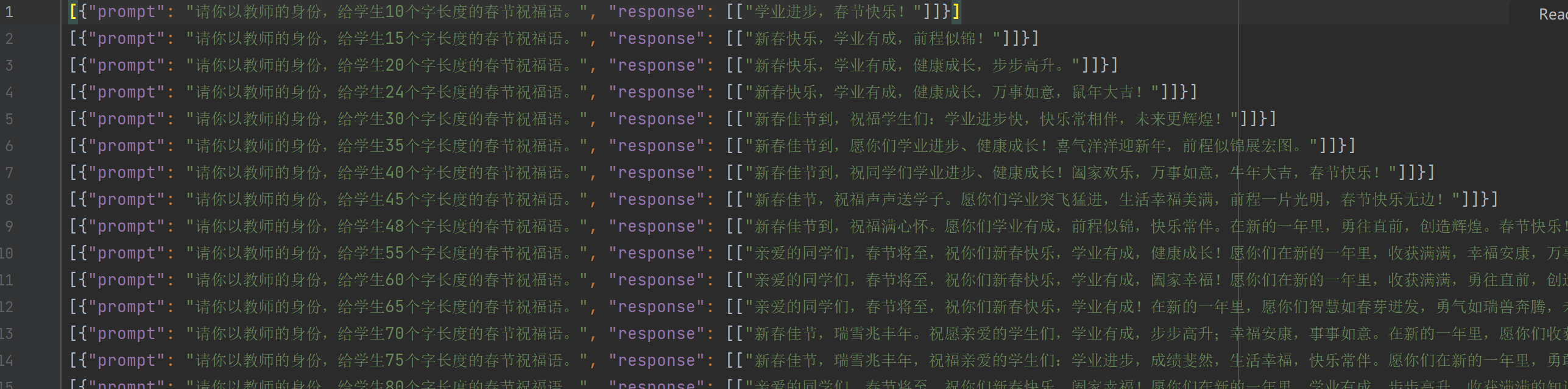
-
57条其它群友自制的公开数据集
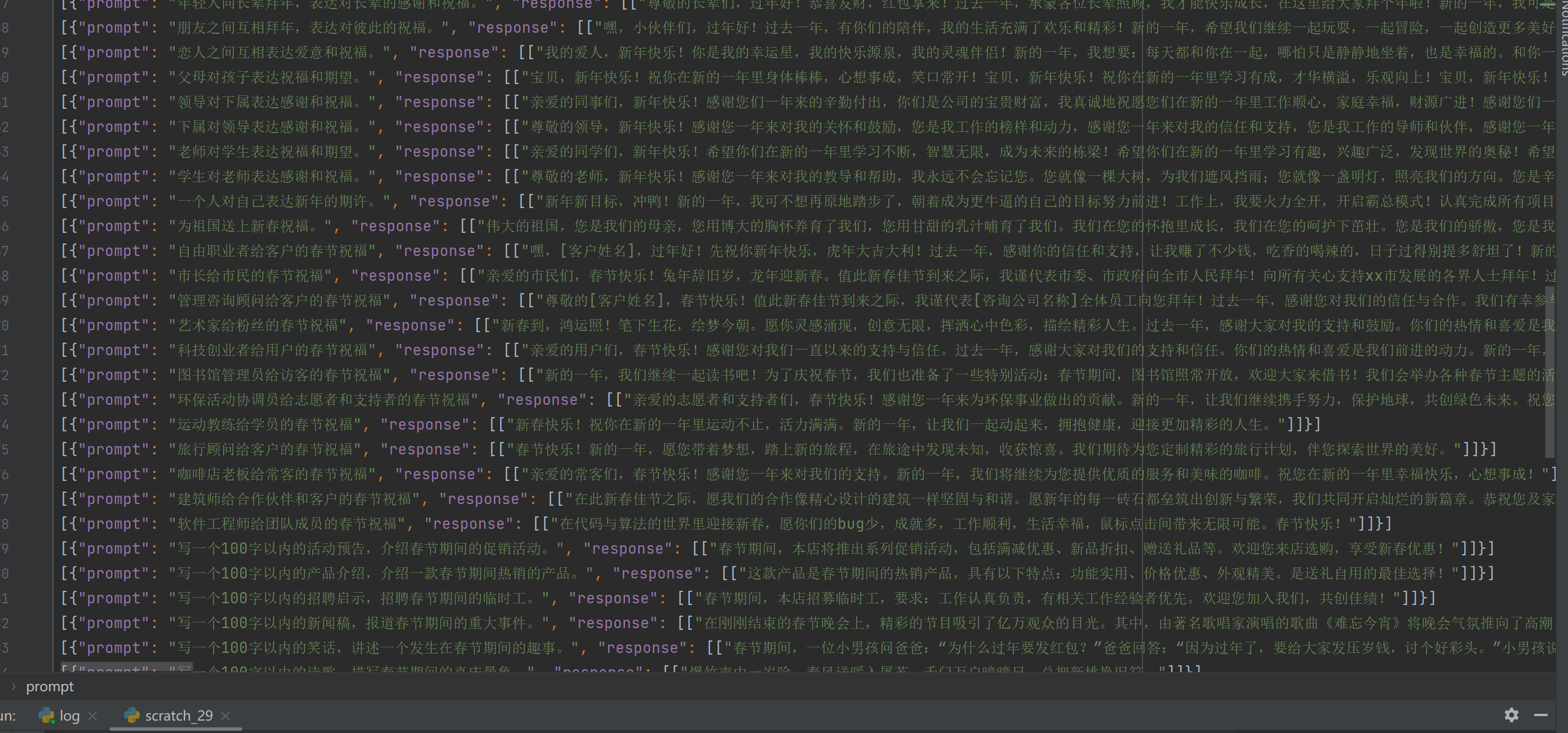
-
2倍56条官方示例相同提问,不同字数回复
合计约334条
-
模型字数标时不管任何提问(如不超过、不高于、低于等等),均替换为最精确的字数。
-
数据集内有约多条重复4-5次重复提问的数据,有约50组完全重复的数据,有进行过去重,去重后约270组数据训练,数据集评分降到7.8左右。说明数据量很重要,重新补充一些新的未重复的promopt对话到334条,评分提升到8,但是无法达到8.36这么高。
-
训练集组成最终结论
对比以下数据集,有以下结论
-
对比1、4、7号数据集效果,可以发现有效的训练集组成结构基本仅为两种,限定为:一是假如你是XXX,请你以XX风格生成XX字祝福语(例:假如你是企业CEO,请以正式鼓励的风格为全公司员工撰写50字的春节祝福语),二是小作文,:以XX为题,写一篇XX字XX文,要求通过XX手法,运用XX,展示XXX。(例:请以喜迎春节为题目,写一篇300字小学生作文,要求通过描绘春节庆典的热闹场景和喜庆氛围,运用形象描写、对比和排比手法,展示春节庆典的欢乐和热烈气氛。)
-
单纯采用祝福语的结构组成数据集不行,进行训练后整体评分和9分比例均最差
-
模型数据样例并非需要很多,数据集多样不重复。像7号数据集,也有可能取得较好的结果。但是像1号和2号数据集,如果有一定的重复数据集比例,可能有助于降低模型评分标准差。
-
prompt中添加思维链引导词可以提升一点点的模型训练效果,对于平均分来说差距可能不大,只在0.18-0.36分附近,主要体现改善模型评估报告中分值分布的比例。对比1号和2号数据集,提升8、9分分值的数据比例,降低最低分值比例和模型评分标准差。可能体现了模型喜好或者一些推理能力上的差距。
-
对于lora来说,epoch 5、epoch 10都是较容易取得较好结果的轮次,全量训练方式不管是模型评分还是字数长度控制以及成本上,对于本轮比赛都是较差的结果。EP3在prompt结构混乱的情况下模型评分标准差较差(可能是数据量上来后结构过于多样),而且无法提高9分数据的比值。对于本类型的数据集结构,学习率在8-9左右是最佳效果
-
不选择7号作为最终评比,主要还是考虑到epcho轮次可能太高会削弱部分通用能力,降低推理能力。后续如果在其基础上进一步优化测试,可能也会有较好的结果。
-
最终进行数据集构造时,以祝福语为基础,不要过多比例的作文生成类型的数据集进行训练,占比约5%-20%即可。其它类型的数据集格式建议1%-5%以内。参考1号、4号、7号数据集示例
-
训练集比例不清楚是否影响,建议1%,loss参数约0.5附近截止即可。整体数据量推荐335条附近,不要过低,否则epoch不适用
评论
