大模型训练——PEFT与LORA介绍
大模型开发/技术交流
- LLM
- 大模型训练
3月19日3486看过
0. 简介
朋友们好,我是练习NLP两年半的算法工程师常鸿宇,今天介绍一下大规模模型的轻量级训练技术LORA,以及相关模块PEFT。Parameter-Efficient Fine-Tuning (PEFT),是huggingface开发的一个python工具,项目地址:
https://github.com/huggingface/peft
其可以很方便地实现将普通的HF模型变成用于支持轻量级fine-tune的模型,使用非常便捷,目前支持4种策略,分别是:
LoRA: LORA: https://arxiv.org/pdf/2106.09685.pdf
Prefix Tuning: https://aclanthology.org/2021.acl-long.353/, https://link.csdn.net/?target=https%3A%2F%2Farxiv.org%2Fpdf%2F2110.07602.pdf
P-Tuning: https://arxiv.org/pdf/2103.10385.pdf
Prompt Tuning: https://arxiv.org/pdf/2104.08691.pdf
今天要介绍的,是其中之一,也是最近比较热门的LORA (LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS)。
1. LORA原理介绍
LORA的论文写的比较难读懂,但是其原理其实并不复杂。简单理解一下,就是在模型的Linear层,的旁边,增加一个“旁支”,这个“旁支”的作用,就是代替原有的参数矩阵W进行训练。
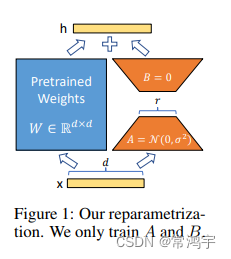
结合上图,我们来直观地理解一下这个过程,输入x xx,具有维度d dd,举个例子,在普通的transformer模型中,这个x xx可能是embedding的输出,也有可能是上一层transformer layer的输出,而d dd一般就是768或者1024。按照原本的路线,它应该只走左边的部分,也就是原有的模型部分。
而在LORA的策略下,增加了右侧的“旁支”,也就是先用一个Linear层A,将数据从d dd维降到r rr,这个r rr也就是LORA的秩,是LORA中最重要的一个超参数。一般会远远小于d dd,尤其是对于现在的大模型,d dd已经不止是768或者1024,例如LLaMA-7B,每一层transformer有32个head,这样一来d dd就达到了4096.
接着再用第二个Linear层B,将数据从r rr变回d dd维。最后再将左右两部分的结果相加融合,就得到了输出的hidden_state。
对于左右两个部分,右侧看起来像是左侧原有矩阵W WW的分解,将参数量从d ∗ d d*dd∗d变成了d ∗ r + d ∗ r d*r+d*rd∗r+d∗r,在r < < d r<<dr<<d的情况下,参数量就大大地降低了。熟悉各类预训练模型的同学可能会发现,这个思想其实与Albert的思想有异曲同工之处,在Albert中,作者通过两个策略降低了训练的参数量,其一是Embedding矩阵分解,其二是跨层参数共享。
在Albert中,作者考虑到词表的维度很大,所以将Embedding矩阵分解成两个相对较小的矩阵,用来模拟Embedding矩阵的效果,这样一来需要训练的参数量就减少了很多。
LORA也是类似的思想,并且它不再局限于Embedding层,而是所有出现大矩阵的地方,理论上都可以用到这样的分解。
但是与Albert不同的是,Albert直接用两个小矩阵替换了原来的大矩阵,而LORA保留了原来的矩阵W,但是不让W参与训练,所以需要计算梯度的部分就只剩下旁支的A和B两个小矩阵。
从论文中的公式来看,在加入LORA之前,模型训练的优化表示为:
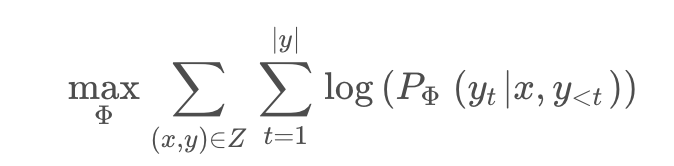
其中,模型的参数用Φ \PhiΦ表示。
而加入了LORA之后,模型的优化表示为:
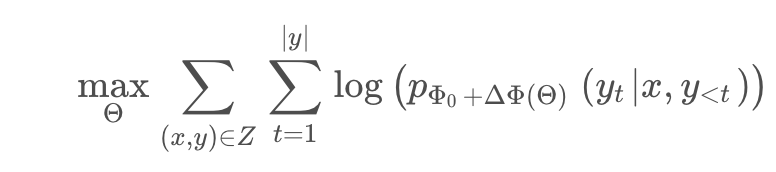
其中,模型原有的参数是Φ 0 \Phi_0Φ 0 ,LORA新增的参数是Δ Φ ( Θ ) \Delta \Phi\left(\Theta\right)ΔΦ(Θ)。
从第二个式子可以看到,尽管参数看起来增加了(多了Δ Φ ( Θ ) \Delta \Phi\left(\Theta\right)ΔΦ(Θ)),但是从前面的max的目标来看,需要优化的参数只有Θ \ThetaΘ,而根据假设,Θ < < Φ \Theta <<\PhiΘ<<Φ,这就使得训练过程中,梯度计算量少了很多,所以就在低资源的情况下,我们可以只消耗Θ \ThetaΘ这部分的资源,这样一来就可以在单卡低显存的情况下训练大模型了。
但是相应地,引入LORA部分的参数,并不会在推理阶段加速,因为在前向计算的时候,Φ \PhiΦ部分还是需要参与计算的,而Θ \ThetaΘ部分是凭空增加了的参数,所以理论上,推理阶段应该比原来的计算量增大一点。
2. 补充资料:低显存学习方法
在介绍代码之前,在这里补充一些低显存学习方法的介绍。参考苏剑林老师的博客:Ladder Side-Tuning:预训练模型的“过墙梯”。其中主要介绍了一篇2022年的论文:《LST: Ladder Side-Tuning for
Parameter and Memory Efficient Transfer Learning》,其中对低显存消耗的训练方法进行了综合地介绍,包括LORA。
论文地址:https://arxiv.org/pdf/2206.06522.pdf
这里借用此文中的配图,来说明一下,在LORA之前的常见的Memory Efficient Transfer Learning方法。
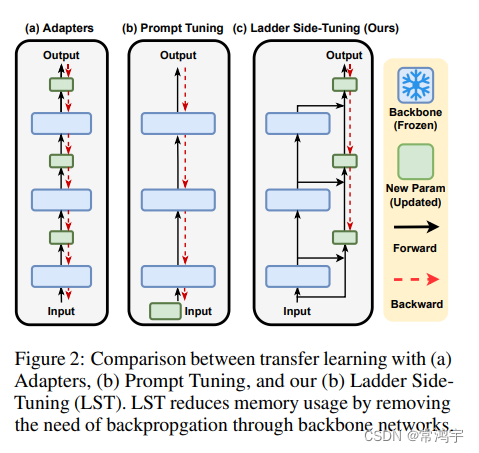
在上图中,非常形象地展示了三种transfer learning的策略。
在普通的adapter中,在各层backbone(蓝色)之间,加入了相对较小的训练参数(绿色),以此来通过调整绿色部分,减少训练参数。然而在这种策略下,缺乏梯度的直接通路(红色虚线),在反向传播中,需要经过所有蓝色的部分。并且,这种结构在并行上也会存在一些困难。
而在prompt tuning中,也存在一些固有的缺陷,它同样缺少梯度的直接通路,每次都需要经过所有的backbone部分。而且,prompt tuning的任务设置过于理想,试图只调节输入端的小部分参数,对深层部分的影响是相当有限的,这就会造成最终fine-tune的效果受到局限。
由于LST不是本文的重点,所以只借助这个示意图来对LORA策略进行说明。而实际上,LST可以看做是在LORA的基础上做出的进一步改进,感兴趣的同学可以阅读原文。
LST与LORA类似,在原有参数矩阵的一侧增加了一个旁支通路,但是二者有些许区别:
-
LORA是将上一步的输入,在分支的时候,分别经过原有参数(类似于图中蓝色部分),以及旁支的通路(绿色可训练参数),二者之间是类似平等的,然后再将结果相加,作为下一层的输入;
-
LST是在将输入先经过原有参数,再与输入本身相加,一起送入旁支通路。
根据LST的论文,其效果是优于LORA的,但是它毕竟不是本文的主角,所以对其原理细节就不做过多的介绍了。
3. PEFT对LORA的实现
接下来是代码部分,我们以HF的PEFT(当前版本0.2.0)为例,介绍一下LORA是如何作用在HF模型上的。
以LORA为例,PEFT模型的使用非常方便,只需要按照原本的方式实例化模型,然后设置一下LORA的config,调用一下get_peft_model方法,就获得了在原模型基础上的PEFT模型,对于LORA策略来讲,就是在某些参数矩阵W的基础上增加了矩阵分解的旁支。在下面的例子中,选择了attention中的q和v的部分做LORA。
# 设置超参数及配置LORA_R = 8LORA_ALPHA = 16LORA_DROPOUT = 0.05TARGET_MODULES = ["q_proj","v_proj",]config = LoraConfig(r=LORA_R,lora_alpha=LORA_ALPHA,target_modules=TARGET_MODULES,lora_dropout=LORA_DROPOUT,bias="none",task_type="CAUSAL_LM",)# 创建基础transformer模型model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)# 加入PEFT策略model = get_peft_model(model, config)
简单介绍一下Lora config相关的配置:

接下来,结合PEFT模块的源码,来看一下LORA是如何实现的。
在PEFT模块中,peft_model.py中的PeftModel类是一个总控类,用于模型的读取保存等功能,继承了transformers中的Mixin类,我们主要来看LORA的实现:
代码位置:https://github.com/huggingface/peft/blob/main/src/peft/tuners/lora.py
class LoraModel(torch.nn.Module):def __init__(self, config, model):super().__init__()self.peft_config = configself.model = modelself._find_and_replace()mark_only_lora_as_trainable(self.model, self.peft_config.bias)self.forward = self.model.forward
从构造方法可以看出,这个类在创建的时候主要做了两件事:
_find_and_replace: 找到所有需要加入lora策略的层,例如q_proj,把它们替换成lora模式;
保留lora部分的参数可训练,其余参数全都固定下来不动。
_find_and_replace的逻辑很清晰,就是先找到需要的做lora的层,然后创建lora层把它替换掉。这里把关键语句列出如下:
找目标层:
# 其中的target_modules在上面的例子中就是"q_proj","v_proj"# 这一步就是找到模型的各个组件中,名字里带"q_proj","v_proj"的target_module_found = re.fullmatch(self.peft_config.target_modules, key)
然后对于每一个找到的目标层,创建一个新的lora层:
# 注意这里的Linear是在该py中新建的类,不是torch的Linearnew_module = Linear(target.in_features, target.out_features, bias=bias, **kwargs)
最后调用
_replace_module方法替换掉原来的linear:
self._replace_module(parent, target_name, new_module, target)
其中这个replace的方法并不复杂,就是把原来的weight和bias赋给新创建的module,然后再分配到指定的设备上:
def _replace_module(self, parent_module, child_name, new_module, old_module):setattr(parent_module, child_name, new_module)new_module.weight = old_module.weightif old_module.bias is not None:new_module.bias = old_module.biasif getattr(old_module, "state", None) is not None:new_module.state = old_module.statenew_module.to(old_module.weight.device)# dispatch to correct devicefor name, module in new_module.named_modules():if "lora_" in name:module.to(old_module.weight.device)
接下来主要看一下Lora层的实现,首先是Lora的基类,可以看出这个类就是用来构造Lora的各种超参数用:
class LoraLayer:def __init__(self,r: int,lora_alpha: int,lora_dropout: float,merge_weights: bool,):self.r = rself.lora_alpha = lora_alpha# Optional dropoutif lora_dropout > 0.0:self.lora_dropout = nn.Dropout(p=lora_dropout)else:self.lora_dropout = lambda x: x# Mark the weight as unmergedself.merged = Falseself.merge_weights = merge_weightsself.disable_adapters = False
然后就要讲到上文中所提到的
Linear类,也就是Lora的具体实现,它同时继承了nn.Linear和LoraLayer。
class Linear(nn.Linear, LoraLayer):# Lora implemented in a dense layerdef __init__(self,in_features: int,out_features: int,r: int = 0,lora_alpha: int = 1,lora_dropout: float = 0.0,fan_in_fan_out: bool = False, # Set this to True if the layer to replace stores weight like (fan_in, fan_out)merge_weights: bool = True,**kwargs,):nn.Linear.__init__(self, in_features, out_features, **kwargs)LoraLayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout, merge_weights=merge_weights)self.fan_in_fan_out = fan_in_fan_out# Actual trainable parametersif r > 0:self.lora_A = nn.Linear(in_features, r, bias=False)self.lora_B = nn.Linear(r, out_features, bias=False)self.scaling = self.lora_alpha / self.r# Freezing the pre-trained weight matrixself.weight.requires_grad = Falseself.reset_parameters()if fan_in_fan_out:self.weight.data = self.weight.data.T
在构造方法中,除了对各个超参数进行配置之外,还对所有参数进行了初始化,定义如下:
def reset_parameters(self):nn.Linear.reset_parameters(self)if hasattr(self, "lora_A"):# initialize A the same way as the default for nn.Linear and B to zeronn.init.kaiming_uniform_(self.lora_A.weight, a=math.sqrt(5))nn.init.zeros_(self.lora_B.weight)
其中lora的A矩阵采用了kaiming初始化,是Xavier初始化针对非线性激活函数的一种优化;B矩阵采用了零初始化,以确保在初始状态Δ W = B A \Delta W =BAΔW=BA为零。(值得注意的是在LORA的论文中,A采用的是Gaussian初始化)。
对于train和eval方法,放在一起介绍,它主要是需要对merge状态进行记录:
def train(self, mode: bool = True):nn.Linear.train(self, mode)self.lora_A.train(mode)self.lora_B.train(mode)if not mode and self.merge_weights and not self.merged:# Merge the weights and mark itif self.r > 0:self.weight.data += (transpose(self.lora_B.weight @ self.lora_A.weight, self.fan_in_fan_out) * self.scaling)self.merged = Trueelif self.merge_weights and self.merged:# Make sure that the weights are not mergedif self.r > 0:self.weight.data -= (transpose(self.lora_B.weight @ self.lora_A.weight, self.fan_in_fan_out) * self.scaling)self.merged = Falsedef eval(self):nn.Linear.eval(self)self.lora_A.eval()self.lora_B.eval()
首先对于新定义的这个Linear层,其本身继承了torch.nn.Linear,所以需要调用nn.Linear.train(self, mode)来控制一下自身原本参数的状态,并且此外它加入了lora_A和lora_B两部分额外的参数,这两部分本质上也是nn.Linear,也需要控制状态。
然后主要来理解一下merge_weights是在做什么,也就是看train中的if分支,not mode说明是eval模式,而self.merge_weights在上文中有介绍,是配置文件中的,意思是评估时是否需要将lora部分的weight加到linear层原本的weight中,not self.merged是状态的记录,也就是说,如果设置了需要融合,而当前状态没有融合的话,就把lora部分的参数scale之后加上去,并且更新self.merged状态;在elif分支中,是为了在训练的过程中,确保linear本身的weights是没有经过融合过的(理论上这一步应该是在eval之后的下一轮train的第一个step触发)。
至于为什么是在train中涉及merge_weights,其实在torch的源码中,nn.Linear.eval()实际上是调用了nn.Linear.train(mode=False),所以这里train方法中的merge_weigths,实际上是在eval中也发挥作用的。
forward中也是类似的原理,正常情况下训练过程应该是走elif的分支:
def forward(self, x: torch.Tensor):if self.disable_adapters:if self.r > 0 and self.merged:self.weight.data -= (transpose(self.lora_B.weight @ self.lora_A.weight, self.fan_in_fan_out) * self.scaling)self.merged = Falsereturn F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)elif self.r > 0 and not self.merged:result = F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)if self.r > 0:result += self.lora_B(self.lora_A(self.lora_dropout(x))) * self.scalingreturn resultelse:return F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)
在了解了这些基本原理之后,就可以类似地去实现更多更加灵活的功能了,例如对transformer的某些层增加lora,而其余的层保持不变等。
以上就是关于LORA的代码实现介绍,在实际的PEFT模块中,还包含了更多更详细完备的设置,本文只是对基本原理和过程进行了介绍,其中包含了部分个人理解,如果错误,还请指出。如果本文对你的学习和工作有所帮助,记得留下一个免费的赞,我们下期再见。
————————————————
版权声明:本文为CSDN博主「常鸿宇」的原创文章
原文链接:https://blog.csdn.net/weixin_44826203/article/details/129733930
如有侵权,请联系千帆社区进行删除
评论
