AI Agent规划能力全面拆解
大模型开发/技术交流
- LLM
2月28日3698看过
“规划今天和每天的工作,然后执行规划”
--撒切尔夫人**
规划,无论对于人类还是智能体而言,本质上是一种预先设定行动的过程,以期望通过这些行动达到特定的目标或解决特定的问题。制定一个好的规划涉及对未来情景的预测、资源的分配、步骤的排序以及对可能出现的挑战的预备应对等诸多因素。
在智能体领域,规划决定了智能体如何自主地在复杂环境中进行操作。智能体通过目标理解与工作流自动化技术,精准地识别和解析复杂的业务目标,自动生成定制化的工作流程,甚至预测并建议潜在的优化方案。
本文详细探讨了智能体规划模块的核心要素,包括长短期规划策略、规划输出格式、反馈与迭代机制,以及用户任务扩展解释优化等。文中还综合比较了当前一些热门智能体项目在这些关键方面的相似性与差异性。
智能体规划简短历史回顾
“Let's think step by step”
--《LLMs are Zero-Shot Reasoners》
《思考,快与慢》是2002年诺贝尔经济学奖得主Daniel Kahneman 于2011年出版的畅销书,在书中提出了人类两种不同的思维方式:快思考与慢思考。快思考是一种自动化运作的思考模式,通常不受严格的自主控制,是人类下意识的反应。慢思考则是需要注意力和认知资源,用于处理复杂的问题和做出决策时的逻辑推理。虽然快慢思考最初是用来描述人类的认知过程,但这一理论也被应用于AI领域。
在AI领域,大模型自回归式的文本生成能力与人类的快速思考模式颇为相似。这类模型依赖于从训练数据中获取的文本关系经验,以生成与上下文最为吻合的文本。这种方法在文本生成过程中表现出高效性,类似于人类在熟悉环境中的直觉反应。然而,这种快思考的方式让大模型在处理需要细致推理的复杂场景时面临挑战。在这种情况下,推理过程通常不能一蹴而就,而是需要通过多个逻辑步骤逐步构建,最终得出答案。
在2022年1月,基于提示的大模型思维链在论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》中被提出,让大模型通过生成一系列的中间推理步骤来提高其解决复杂问题的能力,能够越级打怪。随后,围绕思维链的研究迅速兴起,诞生了多种变种,如CoT-SC、ToT、GoT等。这些变体通常通过增加思维路径的复杂度,以更多的Token消耗为代价,提高了推理路径的准确性,从而有效地提升了大模型解决问题的能力。
与此同时,大模型与工具的交互也开始受到关注中。2021年12月,OpenAI发布了基于GPT-3的微调模型WebGPT,特别强调了模型与Web浏览器交互的能力。通过让模型编写指令,例如“搜索……”、“在页面中查找……”、“引用:……”等指令,WebGPT拥有了使用Web浏览器的能力,并通过观察搜索的结果生成对应的输出。这个项目标志着大模型在工具使用方面的一次重要尝试,涵盖了从单个步骤的工具使用到结果观察等多个方面。

不同种类思维链结构示意图
人们很快发现大模型指令生成和思维链能够很好地结合,让模型能够与虚拟或现实环境交互。其中的典型代表是2022年8月发布的PaLM-SayCan以及2022年Google Brain发布的ReACT结构,其中的主要思想是根据中间步骤的状态来选择最合适的工具并使用。以Saycan为例子,机器(大模型)接收到人类的提示之后,将其转化成对应任务,随后结合可选行动(类似于工具使用)的相关性以及可执行性选择最佳行动并执行,在新状态环境下重复这个过程直到人物完成。ReACT的推理方式类似,通过Thought,Action(以及Action Input),Observation三个步骤的循环执行最终达到Conclusion。这些是早期智能体项目的形态,通常基于短期的动态规划方式来完成思维推理。
在2023年大语言模型应用开始兴起之后,人们看到了大模型的潜力,开始更多地思考大模型应用以及落地方法。早期的智能体项目难以直接使用,缺乏鲁棒性,过于依赖模型自身能力。由此,复杂的智能体系统随之出现,例如CAMEL、MetaGPT、AutoGen、HuggingGPT、AGENTS、ChatDev、XAgent等,这些项目从不同角度提出智能体系统规划模块的改进建议,其中包括长短期规划、规划输出格式、用户提示拓展解释、反馈迭代机制等,接下来我们将从以上维度一同探讨智能体的规划模式:
战略与战术?智能体的长期与短期规划
“最漫长的迂回道路,常常又是达到目的的最短途径“
-- 利德尔·哈特**
在军事和商业领域,战术和战略所指的都是以目标为导向的计划,但战术通常指为达到具体目标而采取的具体行动与决策,关注的是局部目标的达成,而战略是指为实现长期目标而制定的总体计划方针。战术更加注重于快速做出短期的计划,并且具有较强的灵活性与适应性,战略相比之下是一个更为慎重的长期计划,相比于战术根据环境变化而产生的变动较少。战术和战略的概念同样可以用于智能体规划方式的解释当中,其中战术制定类似于智能体的短期规划模式,战略制定类似于智能体的长期规划模式:
战术制定:短期规划
短期规划方法,依托于实时反馈的行动,强调当前环境条件和智能体自身状态对即将采取步骤的决策产生的直接和关键影响。这种规划策略类似于战术制定,为智能体提供了更高的适应性和自由度,使其能够更加灵活地判断和利用各种工具。在早期的智能体研究中,研究者们正试图揭示大型模型的潜能和极限,对大模型的规划能力抱有积极的期望。因此,很多早期的项目以及当前阶段的多智能体协作项目常常采用短期规划方法。这种探索性的研究途径通常更侧重于方法论的创新和理论发展,而不是即时的实用性或商业应用。其中一些典型的项目包括:
AutoGPT(let an LLM decide what to do over and over);
CAMEL(At the next time step, the AI user takes the historical conversation message set and provides a new instruction);
MetaGPT(_observe, _think, _act);
AgentVerse(Expert Recruitment + Collaborative Decision_ Making:Engage the selected agents in joint discussions to devise problem-solving strategies.);
XAgent(Inner_Cycle): (Given a subtask an appropriate ToolAgent is designated ...... The agent employs ReACT for subtask solving;
ProAgent(Instead of directly outputting a plan, the Planner module makes the final decision step by step)
其中有些项目,例如AgentVerse,采用了“专家招募“的方法作为关键工具选择策略,侧重于从众多可用工具中挑选出最适合当前环境和任务的工具,主要通过专家间的讨论确定最合适的工具,或者依据最能适应当前环境的专家的建议来解决手头的任务。专家招募方法的核心思想在于,通过精准地挑选针对特定步骤任务有效的工具,从而使智能体更加高效地适应并解决局部问题。这种方法实际上是一种战术层面的优化手段,旨在通过恰当的工具选择提高智能体的适应性和效率。关于专家招募方法的更深入解释和应用,将在未来的文章中详细阐述。
战略制定:长期规划
在智能体向实际场景落地的进程中,长期规划逐渐受到重视。这种规划方式相对复杂,需要在行动开始前制定详细的步骤清单,这有助于人工参与流程的制定、优化和修改。在复旦大学和米哈游公司联合撰写的智能体综述《The Rise and Potential of Large Language Model Based Agents: A Survey》中,提到某些智能体项目更提倡这种一次性全面地分解宏观目标,并根据预先制定的计划顺序执行的方法。在制定长期计划的过程中,需要考虑宏观目标、环境状态、智能体自身状态、可用工具以及可用资源等多种因素,以确保计划的全面性和可行性。长期规划方法提供了一种更为系统和全面的规划框架,有助于智能体在复杂环境中有效地实现目标,其中的典型项目包括:
BabyAGI (Task List:it creates tasks based on the result of previous tasks and a predefined objective.);
HuggingGPT(we use ChatGPT to conduct task planning when receiving a user request);
AGENTS(allows users to provide fine-grained control and guidance to language agents via an SOP (Standard Operation Process). An SOP defines subgoals/subtasks for the overall task.);
ChatDev(ChatChainConfig.json, which controls the overall development process of ChatDev, including which Phase each step is, how many times each Phase needs to be cycled, whether reflect is needed, etc.);
XAgent(Outer_Cycle):(The PlanAgent first generates an initial plan, which lays down a basic strategy for task execution. )
智能体计中计:长短期规划结合
长期规划和短期规划并不是互斥的概念,相反两者间可以结合,在宏观目标的达成上使用长期规划方式,在局部任务的解决中使用短期规划能力。其中,今年9月发布的XAgent智能体项目使用的”内外循环机制”(Dual-loop mechanism)就是一种长期规划和短期规划结合的方式。外环是长期规划,使用PlanAgent来根据情况来定制生成初始的行动计划, 计划可以在后续行动的过程中进行调整。内环是短期规划,先使用外部系统检索可用的工具,再使用ReACT来解决子任务。这种战术与战略的互补让智能体能够在不同环境中更加高效和适应性强。XAgent智能体通过这种内外循环机制,能够在面对复杂和变化多端的任务时,维持其目标的连贯性和方向性,同时也能够响应即时情况和挑战。
XAgent内外双循环机制结构图
何为规划?智能体规划方式分类
“每一种情况都有适合于它的一个特殊的战略”
-- 安德烈·博弗尔
结构化规划方式
智能体的行动计划可以被结构化地输出,其中,这些计划通常以清晰的步骤和序列展现,并被存储在某种规范化的数据格式中,这种结构化的规划方式对智能体理解和执行任务至关重要。因为每个步骤都设定了明确的目标和预期结果,通过结构化的格式,智能体能够清晰地识别每个中间步骤的状态,从而作出更准确的判断。这种方式也便于对智能体的行动进行监控和评估,以便根据环境变化及时调整计划。目前,智能体项目的结构化规划输出已采用多种模式,其中JSON文件格式应用最为广泛。例如,ChatDev中的流程规划使用了ChatChainConfig.json文件来控制整体的开发流程,涵盖了循环次数、长期规划的调整等方面。
智能体还能生成更加复杂的规划,通过思维链或专用智能体的方式逐步构建,而非一次性完成规划制定。这样的方法能够更加稳定和有效地生成长期规划的工作流程。AGENTS项目就是一个典型的例子,其中智能体利用模型生成或人工生成的SOP进行规划,定义任务的子任务,并允许用户为智能体定制细粒度的工作流程。AGENTS的SOP采用图状的计划列表,每个子任务包含特定的状态,状态中包含提示、工具组件、状态描述和状态间的关系。这使智能体能够根据当前状态适应相应的任务,改变文本生成方式及可调用的功能。

AGENTS智能体结构图
在智能体规划的后续实施中,还可以加入可视化功能,使行动计划更易于人类理解、修改和优化。工程层面上,可以开发低代码平台来编排智能体的规划,让非专业人员也能精准操控智能体,不仅能增强了智能体规划的可用性,还拓宽了其在各领域的应用范围。
非结构化规划方式
基于大模型的自然语言理解能力,出现了大模型特有的基于自然语言的非结构化规划方法,计划可以用一段自然语言文本来描述,并且提供给智能体作为行动的依据。这类非结构化的规划方式易于编写,不需要复杂的结构,更适用于那些不需要严格步骤划分的任务,或者在变化多端的环境中需要快速做出决策的情况。然而,非结构化规划可能不如结构化规划那样易于监控和评估,因为其步骤和目标可能不够明确。
规划的反馈与优化
“规划很少保持不变,并且会根据需要废弃或调整。对愿景要固执,但对规划要灵活。”
-- 约翰·麦克斯韦
随着计划的推进,智能体有时会遇到意料之外的行动结果,此时需要根据结果来对后续步骤进行优化。在这个过程中,智能体首先需要能明确地判断行动执行是否成功,然后再提出潜在的反馈建议。在这种反馈一般来自三个方面:1)借助内部反馈机制;2)与人类互动获得反馈;3)从环境中获得反馈。
短期规划智能体的反馈优化方式是基于更新状态与最终目标间的差距而进行的。举例来说,AgentVerse项目中包括了Evalution和Reward Feedback的部分,Evalution的过程中,行动后环境的新状态将会与目标进行对比, 评估当前状态和期望结果之间的差异,如果对状态不满意,则反馈给下一次迭代以进一步细化。这是一种经典的短期规划方式反馈优化的方式。
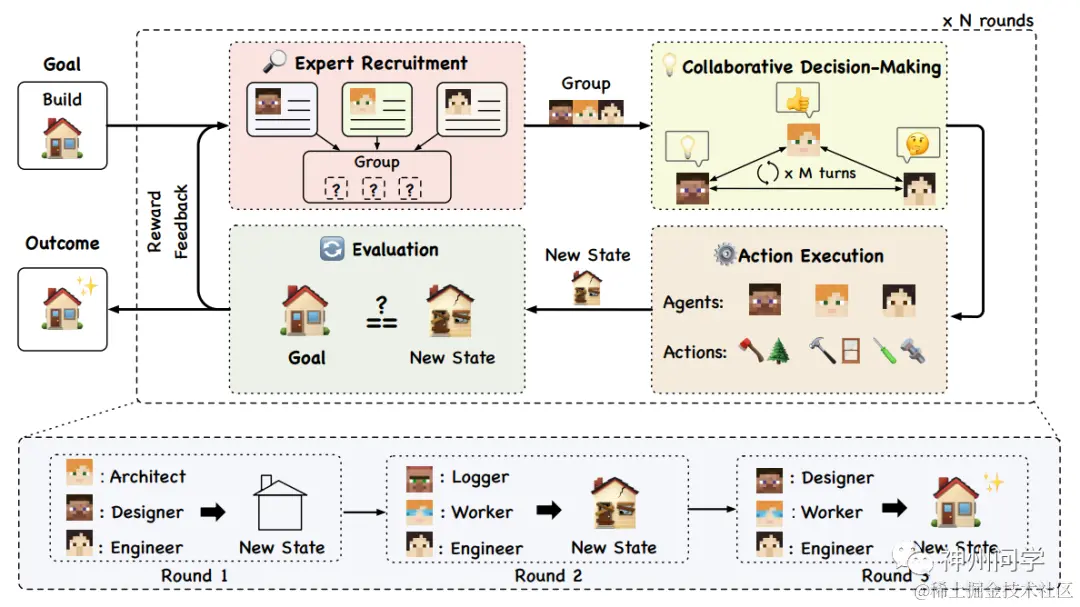
AgentVerse智能体结构图
而长期规划中,智能体在行动开始前生成的规划可以在后期行动执行过程中,根据结果反馈来完善计划。在XAgent项目中,PlanAgent就可以通过子任务拆分、删除、修改和添加的方式进行规划的优化。其中,子任务拆分可以将某个长期规划中的中间步骤拆分为更细粒度的步骤,这便于在遇到难以解决的子任务时用更多的思考步骤来解决任务。
“知你所想“:用户任务拓展解释优化
“很多时候,人们不知道自己想要什么,直到你向他们展示为止”
--史蒂夫·乔布斯
用户的输入有时并不能很好地让大模型理解用户的真正意图,容易出现理解错误的情况。在提示这个概念兴起的时候,就出现了大量的提示优化器项目,例如PromptPerfect这样的基于大模型能力来优化用户提示的项目。这种提示优化的概念也可用于智能体用户任务的拓展解释优化。举例来说,CAMEL中的Task Specifier和 Chatdev中的self_improve模块就是这种用户任务拓展解释优化的模块。CAMEL的Task Specifier模块能够将初步任务/想法作为输入,并利用拓展能力生成特定任务。其提示为:
Here is a task that <ASSISTANT_ROLE> will help <USER_ROLE> to complete: .
Please make it more specific. Be creative and imaginative.
Please reply with the specified task in words or less. Do not add anything else.
Task Specifier模块能够帮助非领域专家智能体更好地完成任务,能起到思维增强的作用。
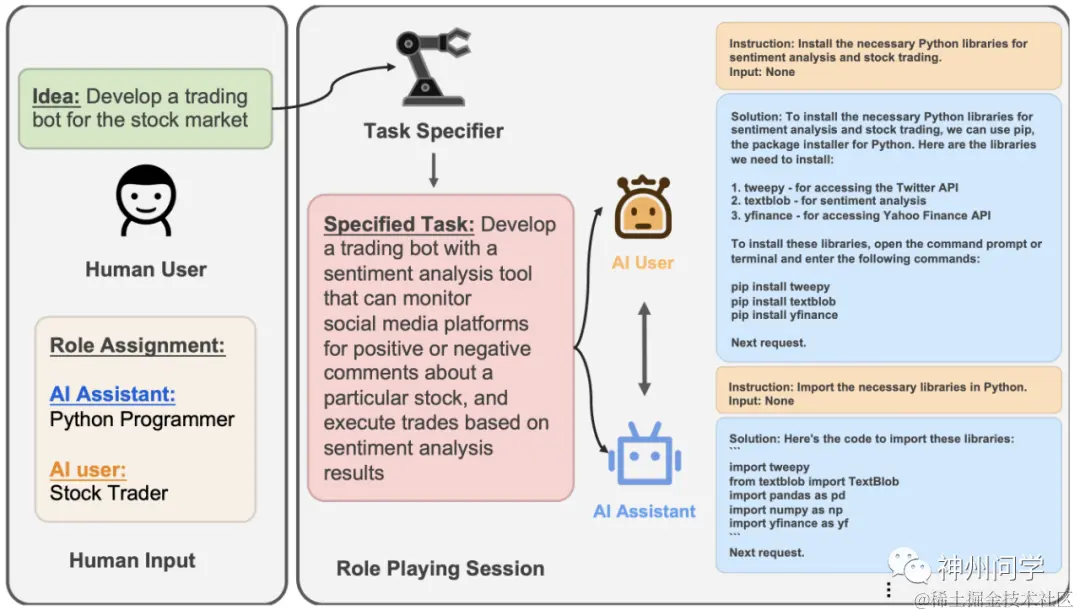
CAMEL智能体结构图
ChatDev中的self_improve模块也是智能体中用于改善用户输入提示的一个模块,用于长期规划器ChatChain当中。
需要注意的是,用户任务拓展优化的过程中会增加信息,可能仍然会出现用户意图的理解偏差,在ChatDev项目中,团队也提出了这一点注意:
“ ⚠️ Attention Model generated prompts contains uncertainty and there may be a deviation from the requirement meaning contained in the original prompt.”
写在最后:
智能体的规划任务是一个多层面、复杂的过程,涵盖了未来情景的预测、资源的合理分配、步骤的有序排列以及对潜在挑战的准备。这一点在人类的决策中也同样体现出来:在缺乏经验的情况下,人们往往无法直接一步得出正确答案,就像学生在解数学题时,往往需要通过在草稿纸上进行大量的中间步骤推理。同样,模型规划也类似于这样的草稿过程,它是模型推理的一个中间环节。
优秀的数学成绩通常不是因为学生拥有更大的脑容量,而是他们掌握了有效的解题方法和思维模式。这一道理同样适用于智能体的规划:一个优秀的智能体需要具备有效的规划方法。未来,我们可以期待出现更高效、更准确的规划方法,这些方法不仅能充分发挥模型的潜力,还能解决更加复杂的问题。这种进步将是AI领域的一个重要里程碑,标志着智能体决策能力的显著提升。
————————————————
版权声明:本文为稀土掘金博主「神州问学」的原创文章
原文链接:https://juejin.cn/post/7337870538138599439
如有侵权,请联系千帆社区进行删除
评论
