前端也可以这样零基础入门Pinecone
大模型开发/技术交流
- LLM
2月26日195看过
前言
向量数据库是构建LLM应用程序架构的关键组成部分,特别是当我们在构建RAG(检索增强生成)类应用的时候,本文我们一起来学习Pinecone。
我们将使用Pinecone来实现文本相似性搜索、图像相似性搜索、异常检测、推荐系统和混合搜索等... 马上就要能实现图搜图了,小激动的。
语义搜索 Semantic Search
在传统的词汇搜索中,主要是字面或模式匹配,我们会用数据库的like查询或ElasticSearch。LLM降低了语义搜索的门槛, 我们可以根据keyword的语义来进行搜索。
自然语义是AIGC类应用的基础,它通过Embedding计算实现,Pinecone存储的就是Embedding向量。当我们将用户输入的keyword也Embedding,就可以和Pinecone里的向量进行cosine相似度计算,从而实现Semantic Search。
简单的Semantic Search Demo
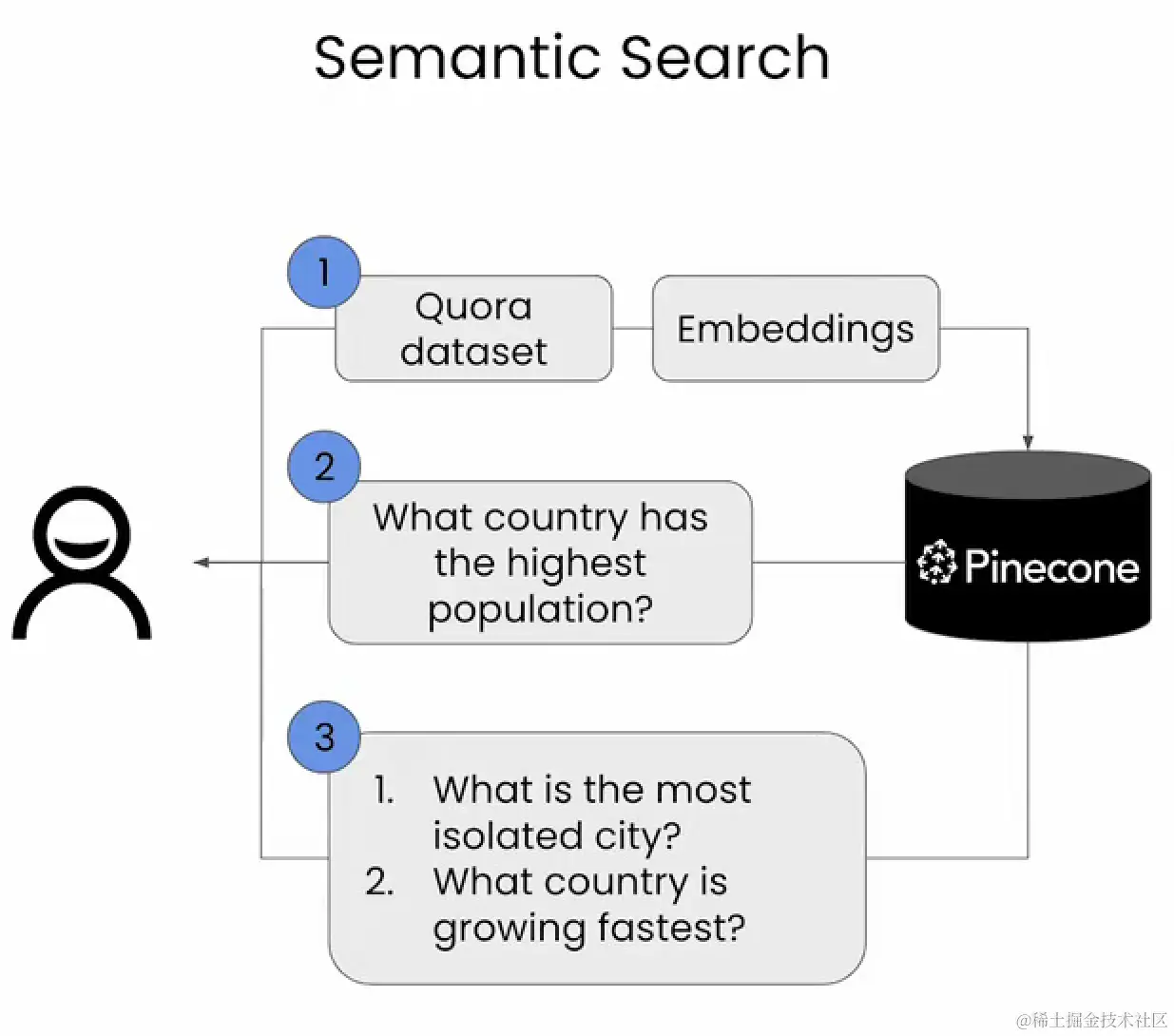
上图是一个
Semantic Search的基本架构图。程序将Quora(问答社区) dataset (数据集),生成嵌入式向量(Embeding)后存入Pinecone。然后程序构建一个QAChain(LangChain),用户就可以向它提出上面的几个问题,得到回答。
-
安装依赖
# HuggingFace 数据集,!pip install datasets# pinecone 向量数据库!pip install pinecone-client# 命令行工具!pip install tqdm
-
引入warning模块,忽略警告信息
import warningswarnings.filterwarnings('ignore')
-
引入相关依赖
# datasets 是由 HugggingFace 提供的数据库加载库,可以方便的加载社区的开源数据集,等下我们会用它加载 quora datasetfrom datasets import load_dataset# sentence_transformers是基于pytorch的句子嵌入计算from sentence_transformers import SentenceTransformer# pinecone 向量数据库 Pinecone是数据库实例, ServerlessSpec是云端存储from pinecone import Pinecone, ServerlessSpecimport osimport time# 开源的深度学习框架import torch# tqdm 是命令行进度条,实时表达当前进展from tqdm.auto import tqdm
-
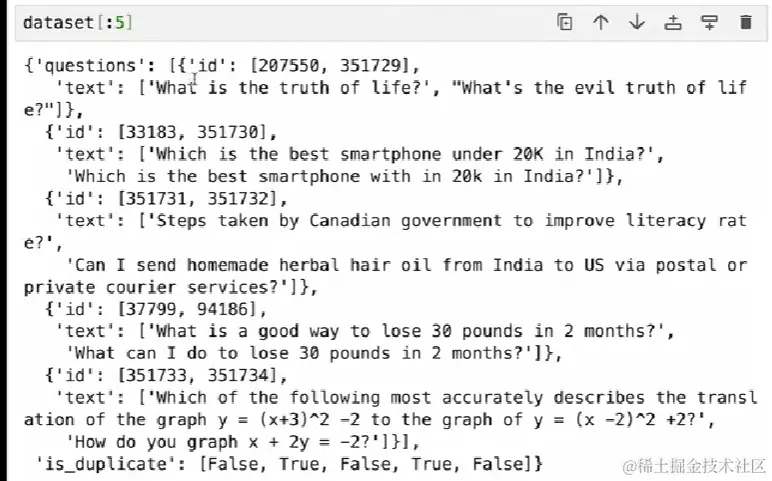
下载数据集,并截取其中的一个子集
# train的意思是训练子集中的一部分dataset = load_dataset('quora', split='train[240000-290000]')# 取其中五条dataset[:5]
-
添加问题
# 准备问题空数组questions = []# 遍历dataset的questionsfor record in dataset['questions']:questions.extend(record['text'])# list 表示有序的可变的数据集合,set去重question = list(set(questions))print('\n'.join(questions[:10]))print('-'*50)print(f'Number of questions: {len(questions)}')

-
嵌入模型的加载
# 查看gpu 能力,如果支持,则gpu 计算,这里数据集不大, 用cpu也行device = 'cuda' if torch.cuda.is_available() else 'cpu'if device != 'cuda':print('Sorry no cuda')# 以前用的是OpenAI, 这里使用的是SentenceTransformer,模型是all-MiniLM-L6-v2# `all-MiniLM-L6-v2` 是一个基于Hugging Face的Sentence Transformers库中的预训练模型model = SentenceTransformer('all-MiniLM-L6-v2', device=device)
这里我们没有用gpu能力,下载进度表表示all-MiniLM-L6-v2模型文件的下载
-
尝试一下嵌入
# 问题query = 'Which city is the most populated in the world?'# 编码 即嵌入xq = model.encode(query)# 将句子编码为一个384维的向量xq.shape
(384,)
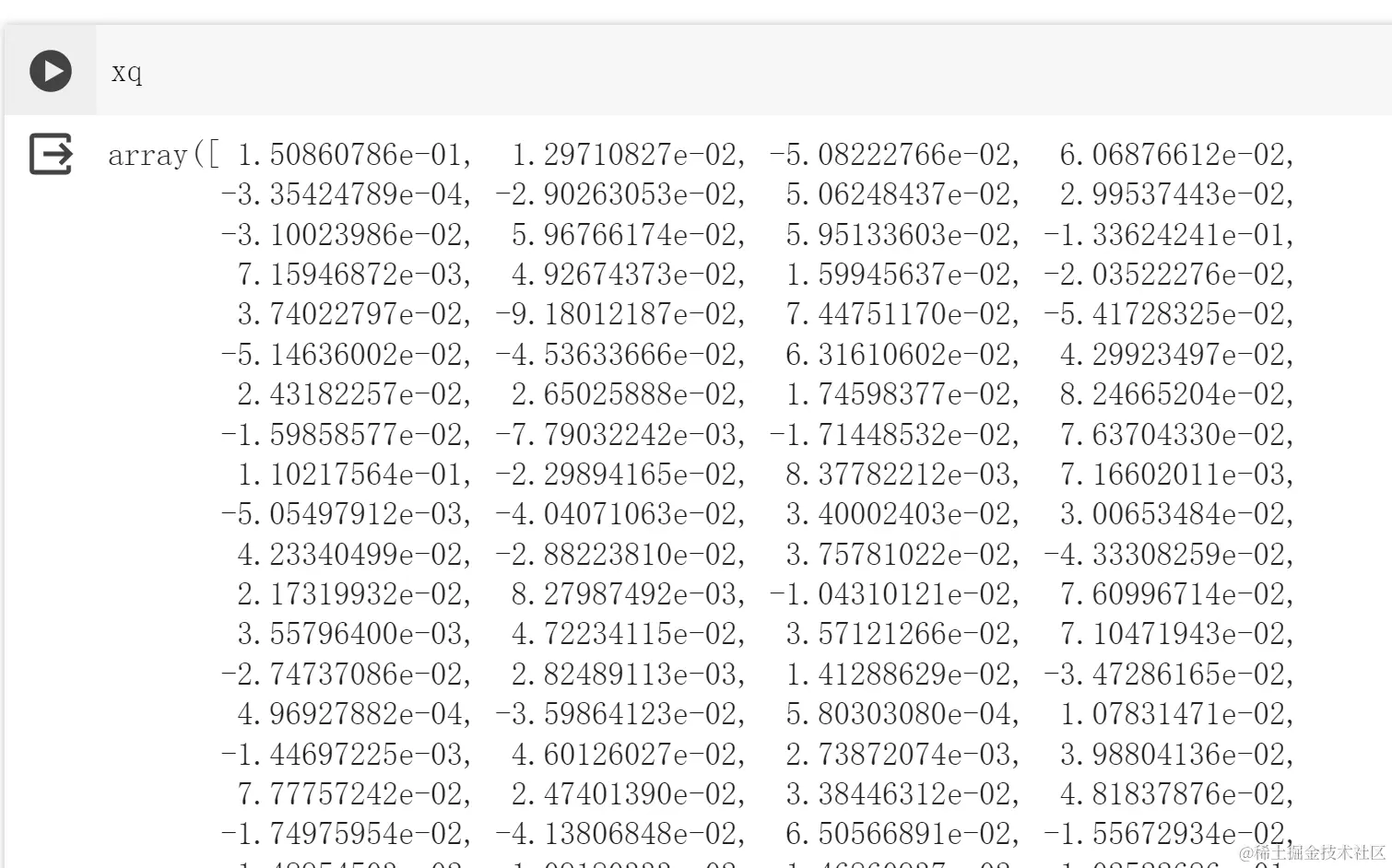
-
实例化pinecone
# 实例化pineconepinecone=Pinecone(api_key='515c9a29-ebf3-4b0b-ab55-e67e50cf31cc')# pinecone里的索引,可以相像为mysql里的tableINDEX_NAME = "dl-ai"# pinecone.list_index() 会返回我们的index列表if INDEX_NAME in (index.name for index in pinecone.list_index()):# 如果已经创建就删除pinecone.delete_index(INDEX_NAME)# 创建索引pinecone.create_index(name=INDEX_NAME,# 维度dimension=model.get_sentence_embedding_dimension(),# cosine 计算相似度metric='cosine',# serverless 的云服务 aws 亚马逊云 地区是 美国西部(俄勒冈)spec=ServerlessSpec(cloud='aws',region='us-west-2'))# 获得indexindex = pinecone.Index(INDEX_NAME)打印indexindex
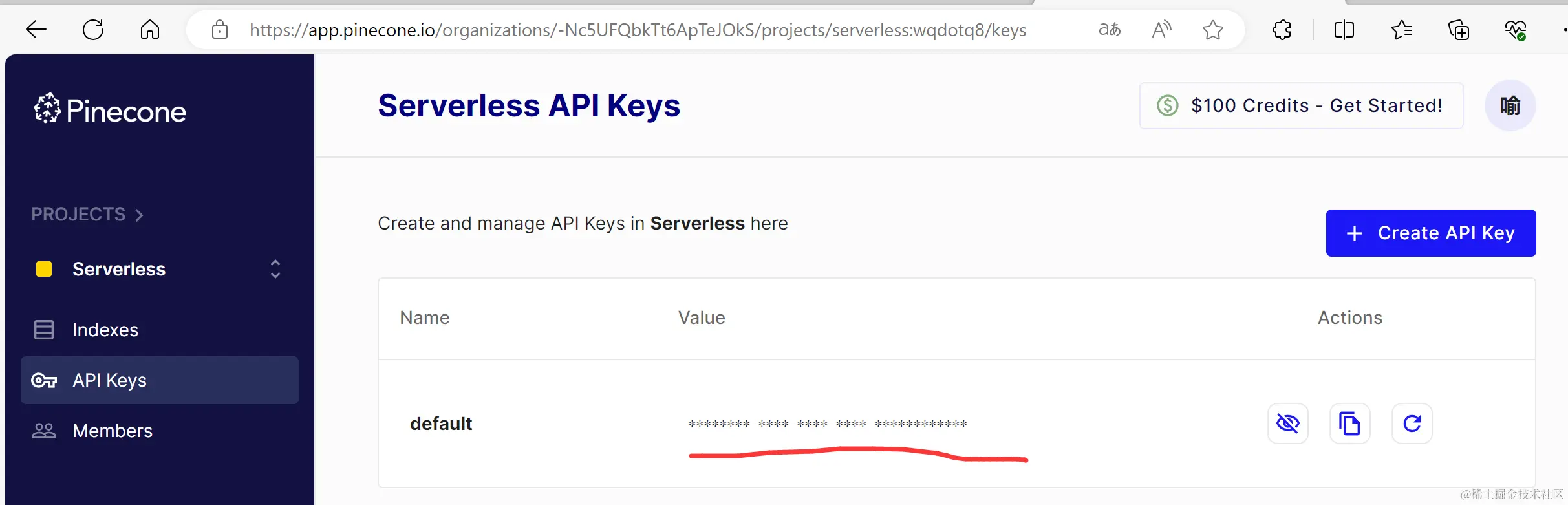
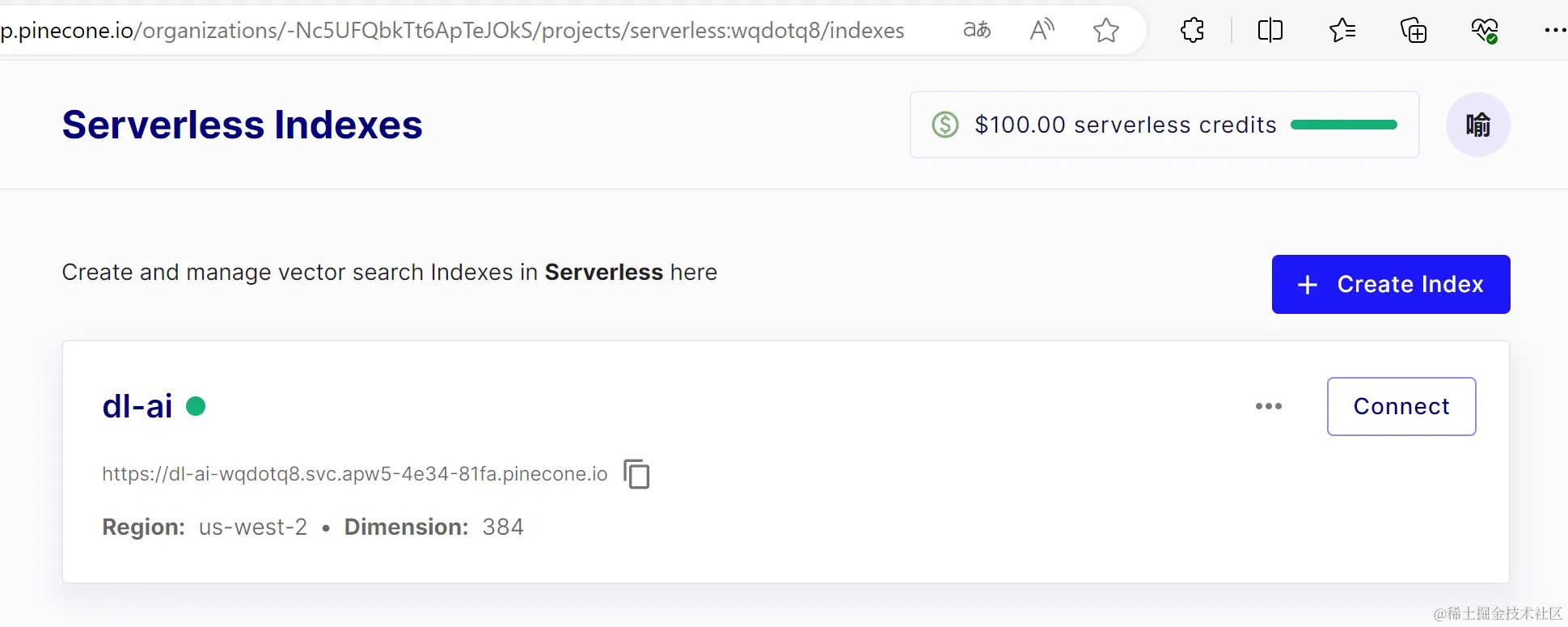
-
数据节片
# 一次处理200个数据batch_size=200# 向量上限为10000vector_limit=10000# 切片操作,要提取的数据是vector_limitquestions = question[:vector_limit]
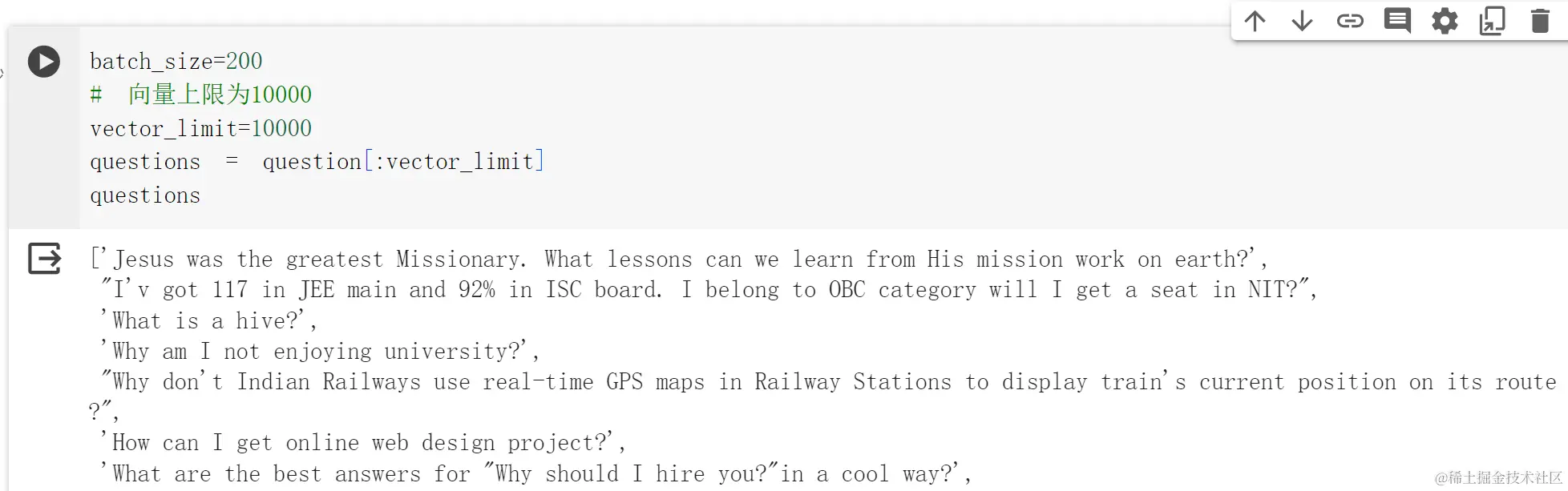
-
上传数据
# tqdm 是进度条工具, 下图显示进度条到60%, 已处理30批数据# range 接受三个参数, 分别是起始位置,结束值, 迭代值 总共要迭代10000/200 = 50for i in tqdm(range(0, len(questions), batch_size)):# 当前最后一条 i的值for 时也会增加 0 200 400....# min 最后一页如果< batch_size 那就取len(questions)i_end = min(i+batch_size, len(questions))# 列表推导式 ids 的值 是 ['0', '1', '2', ....]ids = [str(x) for x in range(i, i_end)]# 数据放在metadatas中, 每一项的结构都是text:textmetadatas=[{'text': text} for text in questions[i:i_end]]# 基于SentenceTransformer embeddingxc = model.encode(questions[i:i_end])#`zip` 是 Python 内置函数,用于将多个可迭代对象(如列表、元组或其他序列)的元素打包成一个个元组,并返回一个 zip 对象records=zip(ids, xc, metadatas)# 添加数据index.upset(vectors=records)

pinecone 里存放的是一个将ids数组、嵌入向量和metadatas 打包后的元组。从下图看,已经存好了。
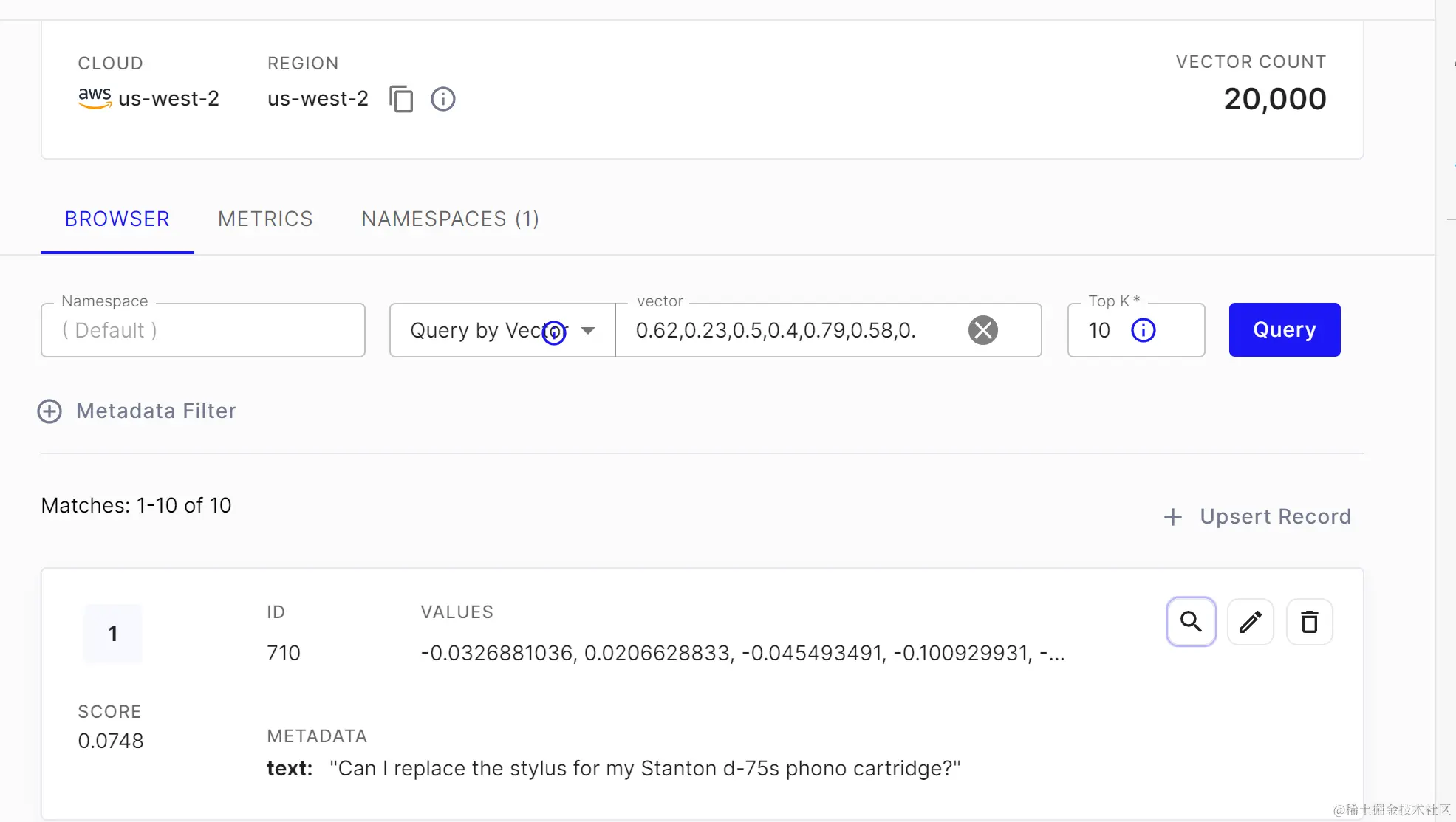
我们要理解下这边为啥会花那么多时间, 一是数量量比较大,二是每次都要进行模型的运行,如果显卡好,就会快很多。我这里花了3分16秒。
-
打印查询内容
index.describe_index_stats()
存成功后,index的状态数据如下:

-
检索器
def run_query(query):embedding = model.encode(query).tolist()results = index.query(vector=embedding, top_k=10, include_metadata=True, include_value=False)for result in results['matches']:print(f"{round(result['score'], 2)}:{result['metadata']['text']}")
这里我们定义了run_query函数, 根据输入调用index上的query方法,得到结果。
-
查询
run_query("which city has the higest population in the world?")
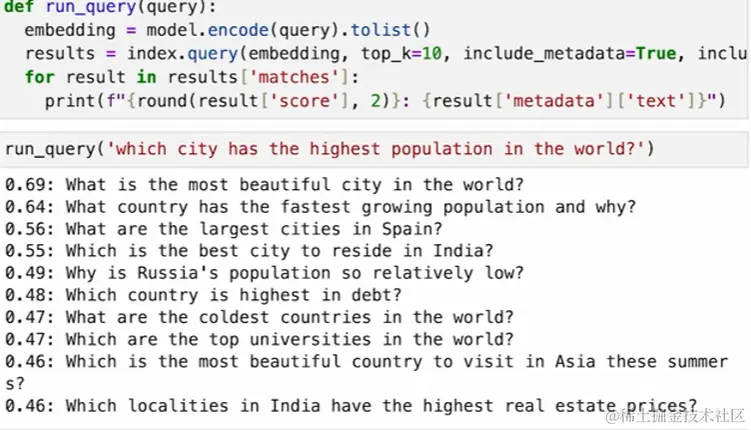
总结
pinecone 的基本流程跑通了,结合huggingface,完美。
参考资料
————————————————
版权声明:本文为稀土掘金博主「旅梦开发团」的原创文章
原文链接:https://juejin.cn/post/7331558973656858624
如有侵权,请联系千帆社区进行删除
评论
