百度文心大模型 ERNIE-Bot-8K 在数据分析场景的评测
大模型开发/技术交流
- LLM
- 大模型推理
- 文心大模型
2月19日3953看过
文心大模型是百度发布的国产大语言模型,具有模型效果优、生成能力强、应用门槛低等独特优势。在 2023 年百度世界大会上,百度创始人兼 CEO 李彦宏正式宣布文心大模型 4.0 发布,并指出大模型更大的价值体现在 AI 应用。本文将结合实际技术评测探讨百度文心大模型 ERNIE-Bot-8K 在企业数据分析场景的应用能力。
去年 10 月开始,Kyligence 通过 《数据分析场景下的大模型能力评测框架(Kyligence LLM Benchmark for Data & Analytics)》 持续对国内外大模型进行评测。本文中,我们使用该框架对文心大模型 ERNIE-Bot-8K 等大模型进行评测,结果详情如下:
-
ERNIE-Bot-8K 综合表现优异 ,为目前评测过最接近 OpenAI GPT 的国产大模型
-
ERNIE-Bot-8K 模型比 ERNIE-Bot-Turbo 有大幅提升,尤其在“指标计算”等方面
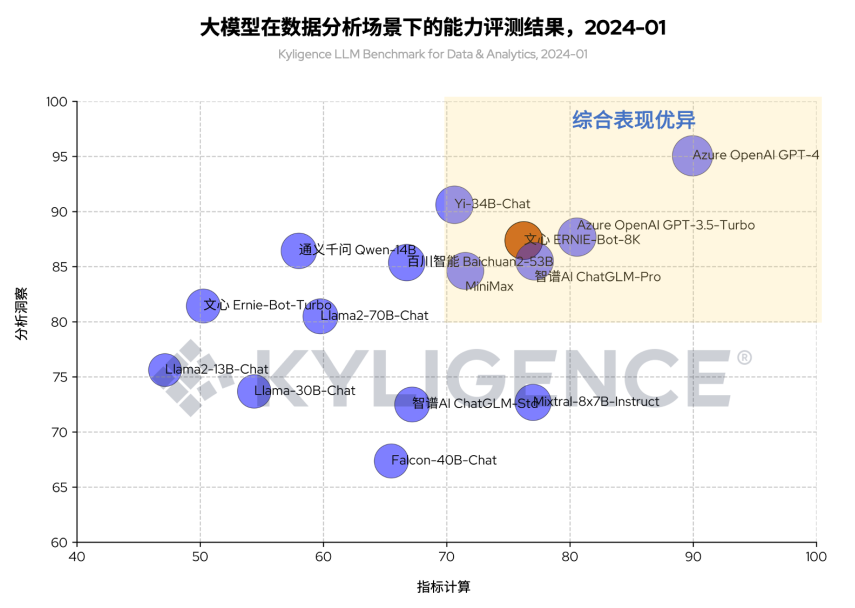
图 1 大模型在数据分析场景下的能力评测结果(棕色为 ERNIE-Bot-8K),2024-01
01 关于测评框架
随着 AI 数智助理 Kyligence Copilot 客户落地场景越来越多,我们也持续改进《数据分析场景下的大模型能力评测框架(Kyligence LLM Benchmark for Data & Analytics)》的评分维度与数据集。在最新版本中,我们共设置意图识别、指标匹配、代码生成(SQL)、代码生成(指标)、洞察生成(SQL)、洞察生成(指标)、图表推荐、报告撰写等 8 个评测维度,并归类为指标计算、分析洞察等两个角度,以此对各个大模型进行实测评分。
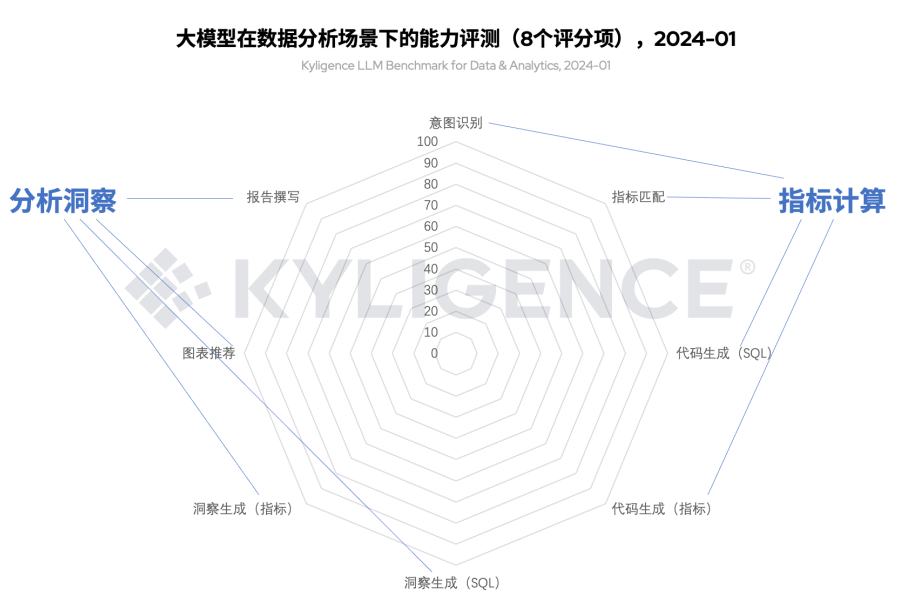
图 2 大模型在数据分析场景下的能力评测维度,2024-01
相比 上一轮评测 ,我们新增了文心 ERNIE-Bot-8K、Mixtral-8x7B-Instruct、Llama2-70B-Chat 等 3 个模型。另外,由于测试数据集更新迭代,我们也对上一轮评测的大模型进行重跑,包括 Azure OpenAI GPT-4、Azure OpenAI GPT-3.5-Turbo、智谱AI ChatGLM-Pro、Yi-34B-Chat、MiniMax、百川智能 Baichuan2-53B、通义千问 Qwen-14B、智谱AI ChatGLM-Std、Falcon-40B-Chat、文心 Ernie-Bot-Turbo、Llama-30B-Chat、Llama2-13B-Chat 等模型,最终各模型评测结果如表 1 所示:
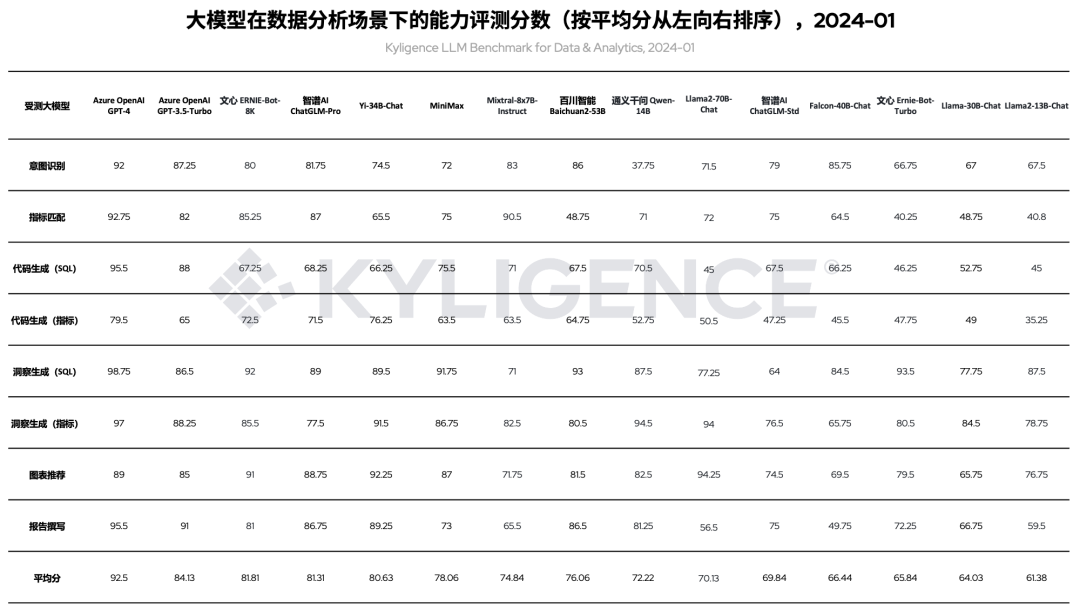
表 1 大模型在数据分析场景下的能力评测分数(按平均分从左向右排序),2024-01
02 ERNIE-Bot-8K 评测解读
为更直观理解本文的评测框架与结果,我们先通过几张截图理解 ERNIE-Bot-8K 应用于数据分析场景的场景表现:
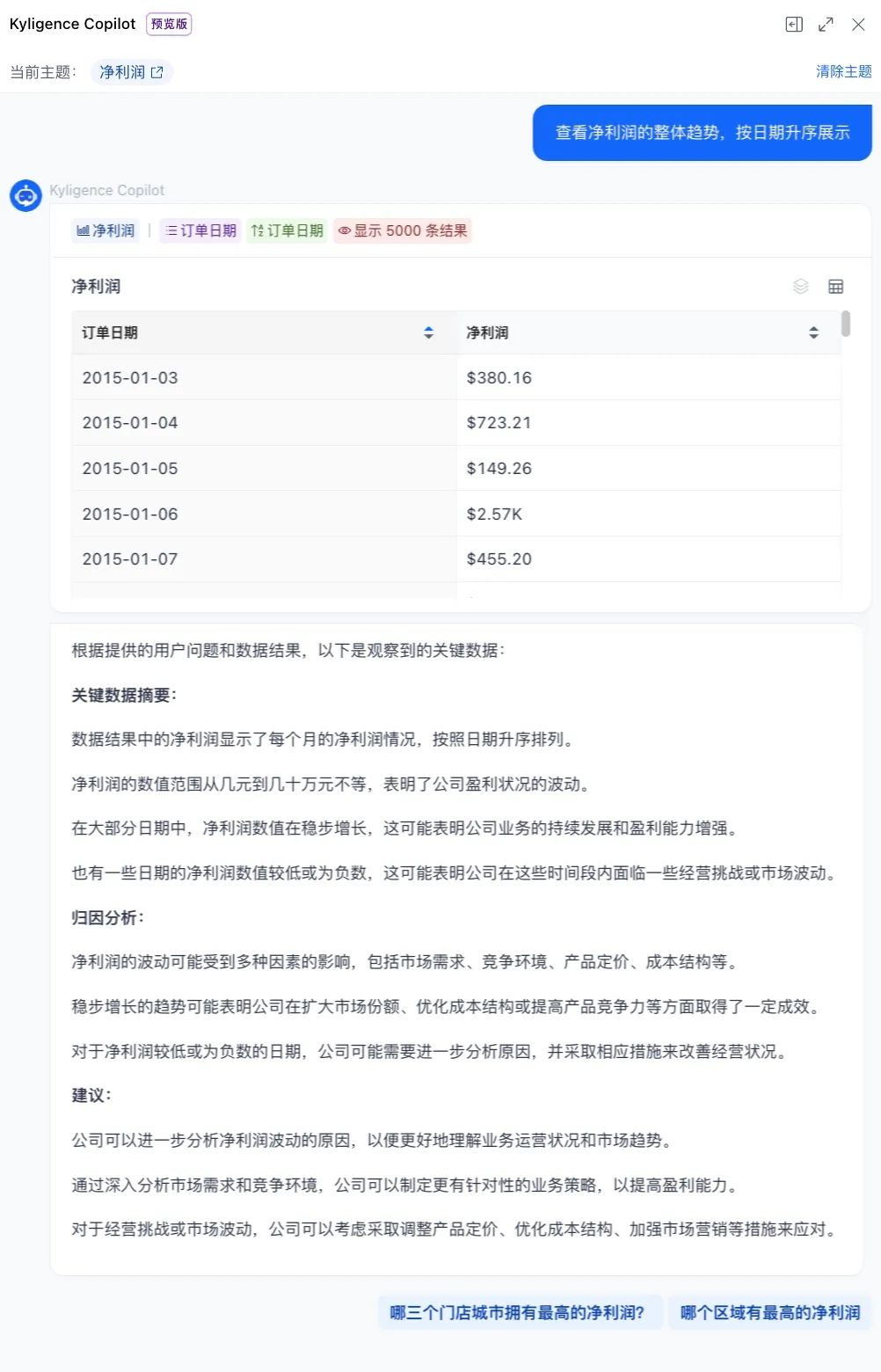
图 2-1 文心大模型 ERNIE-Bot-8K 数据分析场景举例对话式交互分析
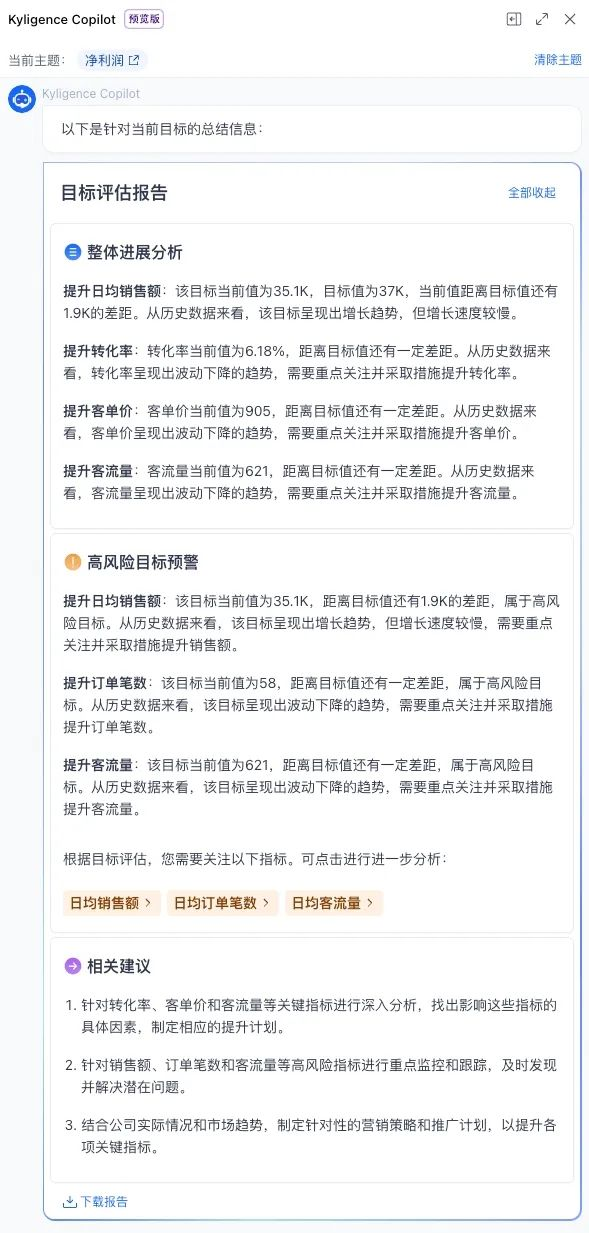
图 2-2 文心大模型 ERNIE-Bot-8K 数据分析场景举例自动生成分析报告
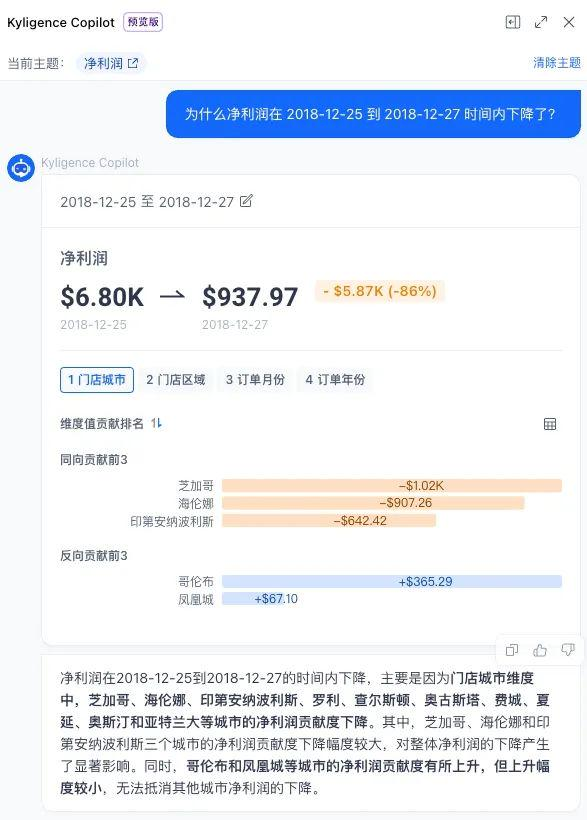
图 2-3 文心大模型 ERNIE-Bot-8K 数据分析场景举例自动指标归因分析
2.1 综合表现优异的国产大模型
图 3 大模型在数据分析场景下的能力评测结果(棕色为 ERNIE-Bot-8K),2024-01
根据表 1 的评测明细数据,在本轮评测中 ERNIE-Bot-8K 综合评分位列前三,是目前评分最高的国产大模型。如图 3 所示,从指标计算和分析洞察两个角度来看,ERNIE-Bot-8K 归属于“综合表现优异”象限。这个象限表示大模型在数据分析场景满足实际落地的基本要求,国内企业在为数据分析场景选型大模型时,往往出于数据合规安全考虑需要选择国产大模型,可参考该象限的数据结果。
2.2 对比 ERNIE-Bot-Turbo 提升明显
本轮评测同时也对 ERNIE-Bot-Turbo 模型进行了评测,从结果看(图 4),ERNIE-Bot-8K 评分比 ERNIE-Bot-Turbo 有更好的表现,尤其在指标匹配、代码生成方面,这使得其在“指标计算”角度较 ERNIE-Bot-Turbo 有明显的提升。
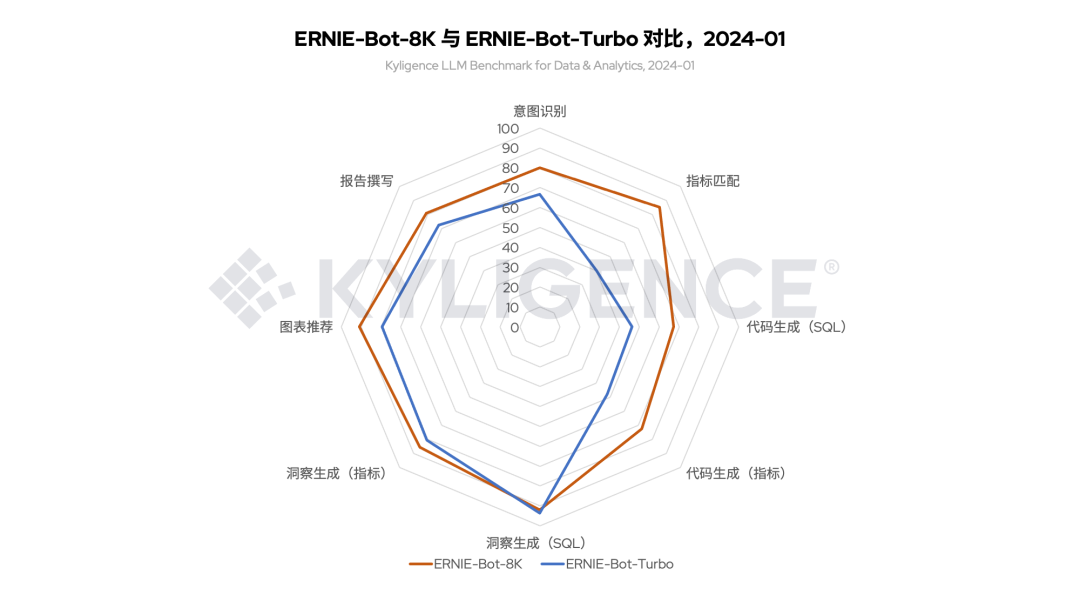
图 4 ERNIE-Bot-8K 与 ERNIE-Bot-Turbo 对比,2024-01
03 ERNIE-Bot-8K 优化建议
3.1 “指标计算”角度的优化建议
如表 1 所示,ERNIE-Bot-8K 在“代码生成(指标)”维度评分比“代码生成(SQL)”维度评分更高,说明 将该模型对接指标平台,并将用户的分析意图转化为访问指标平台的请求,可提升数据分析的准确性 。因此在企业落地数据分析场景时,建议优先考虑大模型 + 指标平台的架构,即大模型负责意图理解和请求生成,指标平台负责指标数据计算与获取,以最大程度提升数据准确度。
3.2 “分析洞察”角度的优化建议
如表 1 所示,ERNIE-Bot-8K 在“可视化推荐”维度表现较好,说明在根据数据推荐可视化展现方面有较好的能力。在提升方面,ERNIE-Bot-8K 在“报告撰写”方面与 Open AI GPT-3.5 差异较大,该场景的特点是长文本、多轮对话、重逻辑推理,为提升 ERNIE-Bot-8K 在该场景下的表现,可加入更多语料进行微调,以提升“报告撰写”的准确度。
04 已知限制和情况说明
-
本次评测数据集基于 Kyligence Copilot 使用场景总结,可能不适用于企业所有数据分析场景
-
本次评测基于各大模型服务的默认配置,未进行任何调参;值得说明的一点是,对大模型服务进行调优可能进一步优化评测结果
-
本次评测针对不同大模型所使用的算力情况如下:
-
文心大模型、Azure OpenAI、智谱 ChatGLM、百川智能、MiniMax、Llama2-70B-Chat、Mixtral-8x7B-Instruct 等大模型均基于厂商或云平台提供的 SaaS 服务,算力资源不详
-
Yi-34B / Falcon-40B / LLaMa-30B / LLaMa2-13B / 通义千问 Qwen-14B 是基于对应的开源模型在实验室私有化部署了本地服务,算力为 4 块 NVIDIA RTX 4090 24GB 显卡
-
结语
在本轮评测中,我们对百度文心大模型 ERNIE-Bot-8K 从不同角度进行深入评测和分析,并给出企业场景落地的优化建议。如果您正在对大模型进行技术选型,或正在探索大模型在数据分析场景的应用落地与优化方案,欢迎加好友一起学习交流。

扫码交流,AI+数据分析落地实践~
评论
