
【千帆SDK】利用千帆平台能力实现大模型全流程开发
大模型开发/技术交流
- LLM
- 大模型训练
- 大模型推理
1月26日2872看过
👏百度智能云千帆SDK正式上线👏
欢迎大家与「千帆小助手」在接下来的时间一同学习千帆SDK的应用~
-
千帆SDK当前已经开源到Github,并将持续的更新迭代,欢迎各位开发者使用订阅,如果有任何问题可以在Github以及评论区提出!
-
请大家点击链接并加🌟:http://github.com/baidubce/bce-qianfan-sdk
前言
本篇主要介绍end-to-end的LLMops流程中的数据->SFT微调->发布->推理流程,使用的SDK版本为0.2.8。建议提前熟悉预测服务相关SDK功能作为前置知识。
!pip install qianfan
在使用前,需要先准备自己的 Access Key 与 Secret Key 用作鉴权,可以从 百度智能云控制台 - 安全认证 处获取,并在 千帆控制台 中创建应用,选择需要启用的服务,详细流程可以参见 文档。
# 初始化百度智能云的IAM ak, sk用于bos和千帆平台的鉴权bce_ak = "your_access_key"bce_sk = "your_secret_key"
数据上传
在进行SFT微调训练前,我们需要准备我们的训练数据;不同的训练任务需要准备不同类型的数据集,具体来说,对于LLM SFT训练任务,需要准备的是
推荐使用的数据格式为
已标注的、非排序的对话数据集推荐使用的数据格式为
jsonl,即每一行文本都包含了一个json字符串,此json需要包含prompt,response两个字段,以下是一个示例,下载方式可在本帖底部加入千帆SDK用户群获取:
[{"prompt" : "你好", "response": [["你需要什么帮助"]]}]
每一行表示一组数据,每组数据中的prompt和response加起来之和字符数不超过8000Token(包括中英文、数字、符号等),超出部分将被截断。
Bos
Bos是百度智能云提供的对象存储云服务,可以高效的存取数据。本篇教程基于Bos,实现本地的数据集到千帆平台数据集的导入:
# 安装千帆 sdk 时会自动安装 bce-python-sdk 依赖,如果不存在可以通过 pip install bce-python-sdk 安装from baidubce.bce_client_configuration import BceClientConfigurationfrom baidubce.auth.bce_credentials import BceCredentialsfrom baidubce.services.bos.bos_client import BosClient# 初始化bos配置BosEndpoint = "bj.bcebos.com"bucket_name = "bucket_name"bos_config = BceClientConfiguration(credentials=BceCredentials(bce_ak, bce_sk), endpoint=BosEndpoint)file_name = "./dataset/sample-text-dialog-unsort-annotated.jsonl"key = "/dataset/dialog01/sample-text-dialog-unsort-annotated.jsonl"prefix = "/dataset/dialog01/"
bos_client = BosClient(bos_config)bos_client.put_object_from_file(bucket_name, key, file_name)
{metadata:{date:u'Fri, 19 Jan 2024 04:52:39 GMT',content_length:u'0',connection:u'keep-alive',content_md5:u'twMrKa2Jleu39LrJu++9AQ==',etag:u'b7032b29ad8995ebb7f4bac9bbefbd01',server:u'BceBos',bce_content_crc_32:u'3754144300',bce_debug_id:u'AAfxrybIjOp7tHN9P6nyRCdMTV0jSaNqLr9tvweg9AnRzWoBGoDKlnOMY15SeGEc9CzJNmc2Dgz/6bVEyJJhTA==',bce_flow_control_type:u'-1',bce_is_transition:u'false',bce_request_id:u'941db320-4203-4450-9dc2-14eb352fbd59'}}
千帆大模型平台鉴权介绍:
在使用千帆 SDK 时,同样需要先进行鉴权。
千帆大模型平台和Bos同处于百度智能云下,所以可以使用同一个AK,SK通过如下方式来进行权限校验:
import osimport qianfanos.environ["QIANFAN_ACCESS_KEY"] = bce_akos.environ["QIANFAN_SECRET_KEY"] = bce_sk
数据导入
在完成了以上从本地到bos的上传过程后,我们就开始着手创建数据集并导入之前上传到bos的数据
from qianfan.resources import Datafrom qianfan.resources.console.consts import DataSetType, DataProjectType, DataTemplateType, DataStorageType# 创建数据集ds = Data.create_bare_dataset(name="hi_sft_ds",data_set_type=DataSetType.TextOnly,project_type=DataProjectType.Conversation,template_type=DataTemplateType.NonSortedConversation,storage_type=DataStorageType.PrivateBos,storage_id=bucket_name,storage_path=prefix)ds
QfResponse(code=200, headers={'Content-Type': 'application/json; charset=utf-8', 'Date': 'Fri, 19 Jan 2024 04:52:40 GMT', 'Content-Length': '587', 'X-Bce-Request-Id': 'b6163044-7db8-4e8b-9570-c12167a5525d', 'X-Bce-Gateway-Region': 'BJ'}, body={'log_id': 'js1uigvzgmyhmwq3', 'result': {'id': 47031, 'datasetId': 'ds-wk9bdt2w9aywxdk0', 'groupId': 38634, 'groupPK': 'dg-3058h6yvaz762jc1', 'groupName': 'hi_sft_dsji', 'versionId': 1, 'projectId': '', 'orgId': '', 'visibility': 'Project', 'dataType': 4, 'projectType': 20, 'templateType': 2000, 'storageType': 'usrBos', 'storageInfo': {'storageId': 'modelrepo-bj-test', 'storagePath': '/modelrepo-bj-test/sdk_test/_system_/dataset/ds-wk9bdt2w9aywxdk0/texts', 'storageName': 'modelrepo-bj-test', 'rawStoragePath': '/sdk_test/', 'region': 'bj'}, 'createTime': '2024-01-19T12:52:39.995268955+08:00'}, 'status': 200, 'success': True}, statistic={'request_latency': 0.179273, 'total_latency': 0.18111269269138575}, request=QfRequest(method='POST', url='https://qianfan.baidubce.com/wenxinworkshop/dataset/create', query={}, headers={'User-Agent': 'python-requests/2.31.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive', 'Content-Type': 'application/json', 'Host': 'qianfan.baidubce.com', 'request-source': 'qianfan_py_sdk_v0.2.8', 'x-bce-date': '2024-01-19T04:52:39Z', 'Authorization': 'bce-auth-v1/2d9f701d872f4f54b69274e9a17ff5b2/2024-01-19T04:52:39Z/300/x-bce-date;request-source;host;content-type/8d86da76566bbb2afc8f1c60dbba654c08e1ca7a90746be0c7e67fab0ae64b8c', 'Content-Length': '186'}, json_body={'name': 'hi_sft_dsji', 'versionId': 1, 'projectType': 20, 'templateType': 2000, 'dataType': 4, 'storageType': 'usrBos', 'storageId': 'modelrepo-bj-test', 'rawStoragePath': '/sdk_test/'}, retry_config=RetryConfig(retry_count=1, timeout=10, max_wait_interval=120, backoff_factor=1, jitter=1, retry_err_codes={})))
# 使用bos进行数据导入from qianfan.resources.console.consts import DataSourceTypeds_id=ds["result"]["id"]import_resp = Data.create_data_import_task(dataset_id=ds_id,is_annotated=True,import_source=DataSourceType.PrivateBos,file_url="bos:/{}{}".format(bucket_name, key))
# 获取数据集详情ds_info = Data.get_dataset_info(ds_id)
监听导入状态
由于数据集导入是一个耗时任务,所以我们需要等待其完成才能进行下一步的动作,这里我们通过轮询的方式简单的监听任务状态直到数据完成导入成功。
import timefrom qianfan.resources.console.consts import DataImportStatuswhile True:# 获取数据集详情ds_info = Data.get_dataset_info(ds_id)import_status = ds_info["result"]["versionInfo"]["importStatus"]if import_status == DataImportStatus.Finished.value:print("dataset import finish, ready to release")breakprint("current_import_status", import_status)time.sleep(10)
current_import_status 1current_import_status 1dataset import finish, ready to release
发布数据集
恭喜你到达了进行SFT训练的最后一步,我们已经完成了数据集的准备,现在需要发布数据集。
Note:
发布数据集后后无法再进行数据集的处理,导入或者修改!
from qianfan.resources.console.consts import DataReleaseStatus# 发布 并监听数据集发布状态resp = Data.release_dataset(ds_id)while True:# 获取数据集详情ds_info = Data.get_dataset_info(ds_id)release_status = ds_info["result"]["versionInfo"]["releaseStatus"]if release_status == DataReleaseStatus.Finished.value:print("dataset release finish, ready to train")breakprint("current_release_status", release_status)time.sleep(10)
current_release_status 1current_release_status 1dataset release finish, ready to train
至此,数据部分的准备已经完成!我们话不多说赶紧开始LLM的Finetune:
Finetune
目前千帆平台支持如下 SFT 相关操作:
-
创建训练任务
-
创建任务运行
-
获取任务运行详情
-
停止任务运行
创建SFT任务
创建训练任务需要提供任务名称
name和任务描述description,返回结果在result字段中,具体字段与API 文档一致。
from qianfan.resources import FineTune# 创建任务resp = FineTune.create_task(name="test_sdk_taskqf02", description="for_eb_turbo1")# 获取任务IDtask_id = resp["result"]["id"]task_id
18548
创建任务运行
创建任务运行需要提供该次训练的详细配置,例如模型版本(
trainType)、数据集(trainset)等等,且不同模型的参数配置存在差异,具体参数可以参见API 文档。
# 创建任务运行,具体参数可以参见 API 文档create_job_resp = FineTune.create_job({"taskId": task_id,"baseTrainType": "ERNIE-Bot-turbo","trainType": "ERNIE-Bot-turbo-0725","trainMode": "SFT","peftType": "LoRA","trainConfig": {"epoch": 1,"learningRate": 0.00003,# "batchSize": 4,"maxSeqLen": 4096},"trainset": [{"type": 1,"id": ds_id}],"trainsetRate": 20})create_job_resp
QfResponse(code=200, headers={'Date': 'Fri, 19 Jan 2024 04:53:44 GMT', 'Content-Type': 'application/json; charset=utf-8', 'Content-Length': '45', 'tracecode': '32246285101049976330011912', 'Set-Cookie': 'BAIDUID=6E3A3D915EF7136FBD09B498AB2FAB5A:FG=1; expires=Sat, 18-Jan-25 04:53:44 GMT; max-age=31536000; path=/; domain=.baidu.com; version=1', 'P3P': 'CP=" OTI DSP COR IVA OUR IND COM "', 'X-Bce-Request-Id': '7cc1fe6d-b34f-4057-bf72-1918e2461210', 'X-Bce-Gateway-Region': 'BJ'}, body={'log_id': '3785581218', 'result': {'id': 10989}}, statistic={'request_latency': 2.96891, 'total_latency': 2.971031927037984}, request=QfRequest(method='POST', url='https://qianfan.baidubce.com/wenxinworkshop/finetune/createJob', query={}, headers={'User-Agent': 'python-requests/2.31.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive', 'Content-Type': 'application/json', 'Host': 'qianfan.baidubce.com', 'request-source': 'qianfan_py_sdk_v0.2.8', 'x-bce-date': '2024-01-19T04:53:41Z', 'Authorization': 'bce-auth-v1/2d9f701d872f4f54b69274e9a17ff5b2/2024-01-19T04:53:41Z/300/x-bce-date;request-source;host;content-type/6b4dc43278b8f8dfd5823fd8a07d58bebdfddd0d206f7a62b7c51ce2099b2f9d', 'Content-Length': '261'}, json_body={'taskId': 18548, 'baseTrainType': 'ERNIE-Bot-turbo', 'trainType': 'ERNIE-Bot-turbo-0725', 'trainMode': 'SFT', 'peftType': 'LoRA', 'trainConfig': {'epoch': 1, 'learningRate': 3e-05, 'maxSeqLen': 4096}, 'trainset': [{'type': 1, 'id': 47031}], 'trainsetRate': 20}, retry_config=RetryConfig(retry_count=1, timeout=10, max_wait_interval=120, backoff_factor=1, jitter=1, retry_err_codes={})))
这一步会监听训练
进度,同时也观察训练任务状态,根据训练的模型大小,方法等的不同,需要一定的时间才能进行下一步模型发布。
import timejob_id = create_job_resp["result"]["id"]while True:job_status_resp = FineTune.get_job(task_id=task_id, job_id=job_id)job_status = job_status_resp["result"]["trainStatus"]print("job status:", job_status)if job_status != 'RUNNING':breaktime.sleep(60)
发布模型
发布新模型需要指定task_id和iterationsId(job_id);
如果是希望进行同个模型的多次迭代更新
如果是希望进行同个模型的多次迭代更新
from qianfan.resources import Modelsft_task_publish_resp = Model.publish(is_new=True, model_name="test_sdk_ebt1", version_meta={"taskId": task_id, "iterationId": job_id})# 获取model_id and versionmodel_id = sft_task_publish_resp["result"]["modelId"]model_version = sft_task_publish_resp["result"]["version"]print("model_id:", model_id)print("model_version", model_version)
model_id: 12243model_version 1
# 获取模型版本信息:model_version_list = Model.list(model_id=model_id)model_version_id: int = 0for m in model_version_list["result"]["modelVersionList"]:if m["modelId"] == model_id and m["version"] == model_version:model_version_id = m["modelVersionId"]if model_version_id == 0:raise ValueError("not model version")print("model_version_id", model_version_id)
model_version_id 15176
监听模型版本详情状态
模型任务在训练FINISH之后,需要等待模型版本状态为READY,模型才算完全发布到模型仓库中,这一步也可以在web控制台中的我的模型/详情中看到。
这一步会进行模型发布,保存到我的模型仓库中,根据模型的大小,可能需要等待若干分钟之后才能进行下一步模型服务部署。
这一步会进行模型发布,保存到我的模型仓库中,根据模型的大小,可能需要等待若干分钟之后才能进行下一步模型服务部署。
# 获取模型版本详情# 模型版本状态有三种:Creating, Ready, Failedwhile True:model_detail_info = Model.detail(model_version_id=model_version_id)model_version_state = model_detail_info["result"]["state"]print("current model_version_state:", model_version_state)if model_version_state != "Creating":breaktime.sleep(60)
current model_version_state: Ready
模型评估
用户可以在创建模型服务之前,先使用平台提供的模型评估功能对训练好的模型进行评估。
我们以金融新闻摘要数据集作为我们评估使用的数据集
我们以金融新闻摘要数据集作为我们评估使用的数据集
eval_create_response = Model.create_evaluation_task(name="fin_news_testsss",version_info=[{"modelId": model_id,"modelVersionId": model_version_id,},],dataset_id=15067,eval_config={"evalMode": "rule","scoreModes": ["similarity","accuracy",],},dataset_name="FinCUGE_FinNA",).bodyeval_task_id = eval_create_response["result"]["evalId"]print("eval_task_id", eval_task_id)
eval_task_id 3080
由于评估也是一项非常耗时的任务,因此我们同样需要监听任务状态,直到评估完成。
# 缓冲,等待任务真正开始运行time.sleep(5)while True:eval_info = Model.get_evaluation_info(eval_task_id)eval_state = eval_info["result"]["state"]print("current eval_state:", eval_state)if eval_state != "Doing":breaktime.sleep(60)
eval_result = Model.get_evaluation_result(eval_task_id)print(eval_result["result"])
[{'modelName': 'test_sdk_ebt1ht', 'modelVersion': '1', 'modelVersionSource': 'Train', 'evalMode': 'rule', 'evaluationName': 'fin_news_testsss', 'id': '65aa1744e169f906e3d16656', 'modelVersionId': 15176, 'modelId': 12243, 'userId': 20, 'evaluationId': 3080, 'effectMetric': {'accuracy': 0.006076389, 'f1Score': 0.251639, 'rouge_1': 0.2942075, 'rouge_2': 0.132045, 'rouge_l': 0.22818616, 'bleu4': 0.06821427, 'avgJudgeScore': 0, 'stdJudgeScore': 0, 'medianJudgeScore': 0, 'scoreDistribution': None, 'manualAvgScore': 0, 'goodCaseProportion': 0, 'subjectiveImpression': '', 'manualScoreDistribution': None}, 'performanceMetric': {}}]
评估完成后的详细评估报告目前仅支持在网页查看
创建模型服务
这一步用于创建一个在线服务,获取到service Id
from qianfan.resources import Servicefrom qianfan.resources.console.consts import DeployPoolTypeg = Service.create(model_id = model_id,# iteration_id = model_version_id,model_version_id = model_version_id,name="testsebqf1",uri="sdkqf1",replicas=1,pool_type=DeployPoolType.PrivateResource)
svc_id = g["result"]["serviceId"]svc_id
6116
部署模型服务
这一步由于需要涉及到资源的服务逻辑,所以目前需要在web上操作付费,完成付费之后即可使用模型推理服务。
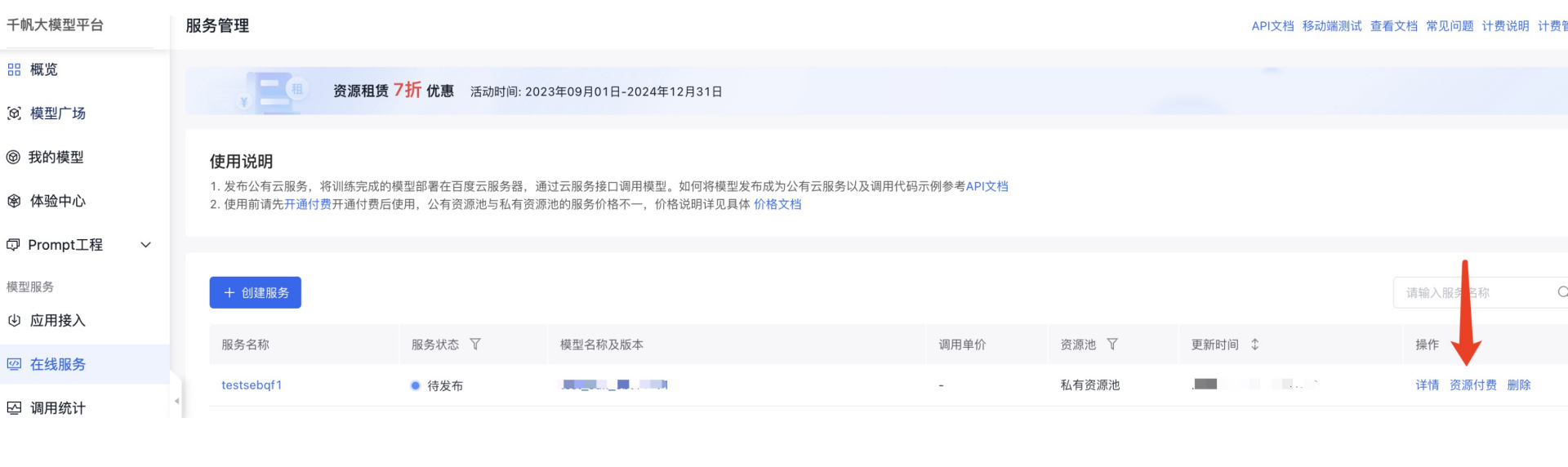
# 资源付费完成后,serviceStatus会变成Deploying,查看模型服务状态, 直到serviceStatus变成部署完成,得到model_endpoint# 这一步涉及到资源调度,需要等待5-20分钟不等while True:resp = Service.get(id = svc_id)svc_status = resp["result"]["serviceStatus"]print("svc deploy status:", svc_status)if svc_status in ["Done", ""]:sft_model_endpoint=resp["result"]["uri"]breaktime.sleep(30)print("sft_model_endpoint:", sft_model_endpoint)
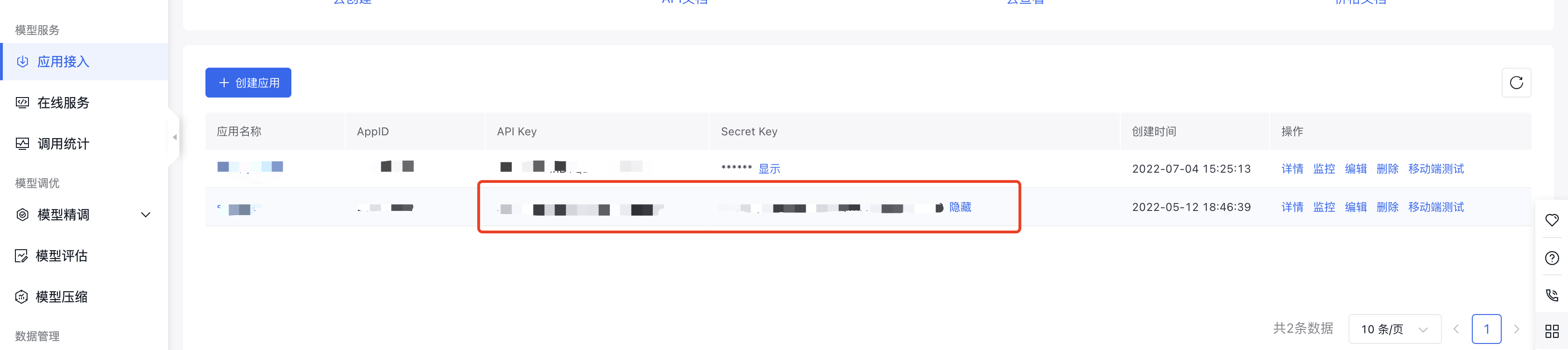
访问SFT模型服务
在访问服务之前,首先需要配置预测服务应用的AK/SK,可以从控制台中的应用接入里获取:
import qianfanchat_comp = qianfan.ChatCompletion(endpoint=sft_model_endpoint)msgs = qianfan.Messages()msgs.append(message="你好,你是谁?", role=qianfan.QfRole.User)chat_resp = chat_comp.do(messages=msgs)chat_resp
总结
至此,你已经通过SFT训练成功的微调出自己的大语言模型,SFT是一个很好的手段,用于针对于特定场景下的语料进行模型特化,以增强模型在某方面的能力,非常适合对于垂直领域内的应用。除了SFT之外,千帆平台还提供了RLHF功能,SDK也将在将来持续跟进LLMOps能力。
联系我们
千帆SDK用户群

评论
