4
千帆大模型平台的初体验——SFT、RLHF训练
大模型开发/技术交流
- SFT
- 开箱评测
- 社区上线
2023.10.035474看过
前言
最近百度智能云千帆大模型面向大众开放了公测服务,作为一名对ai大模型有浓厚兴趣的大学生,我在国庆假期期间进行了申请体验千帆大模型,申请地址如下: https://console.bce.baidu.com/qianfan/data/etl/list
本文的主要内容为: 初探干帆大模型,了解其全流程的开发,并进行一个小demo的场景使用
初探千帆大模型
根据刚刚的网址申请后,即可进入百度智能云的控制台页面,左边对应着功能,可以看到功能还是比较全面的,数据的导入——>数据的处理——>数据标注——>模型开发——>模型纳管——>部署上线基本上常用的功能都有,下面我们来一起实验一下吧。
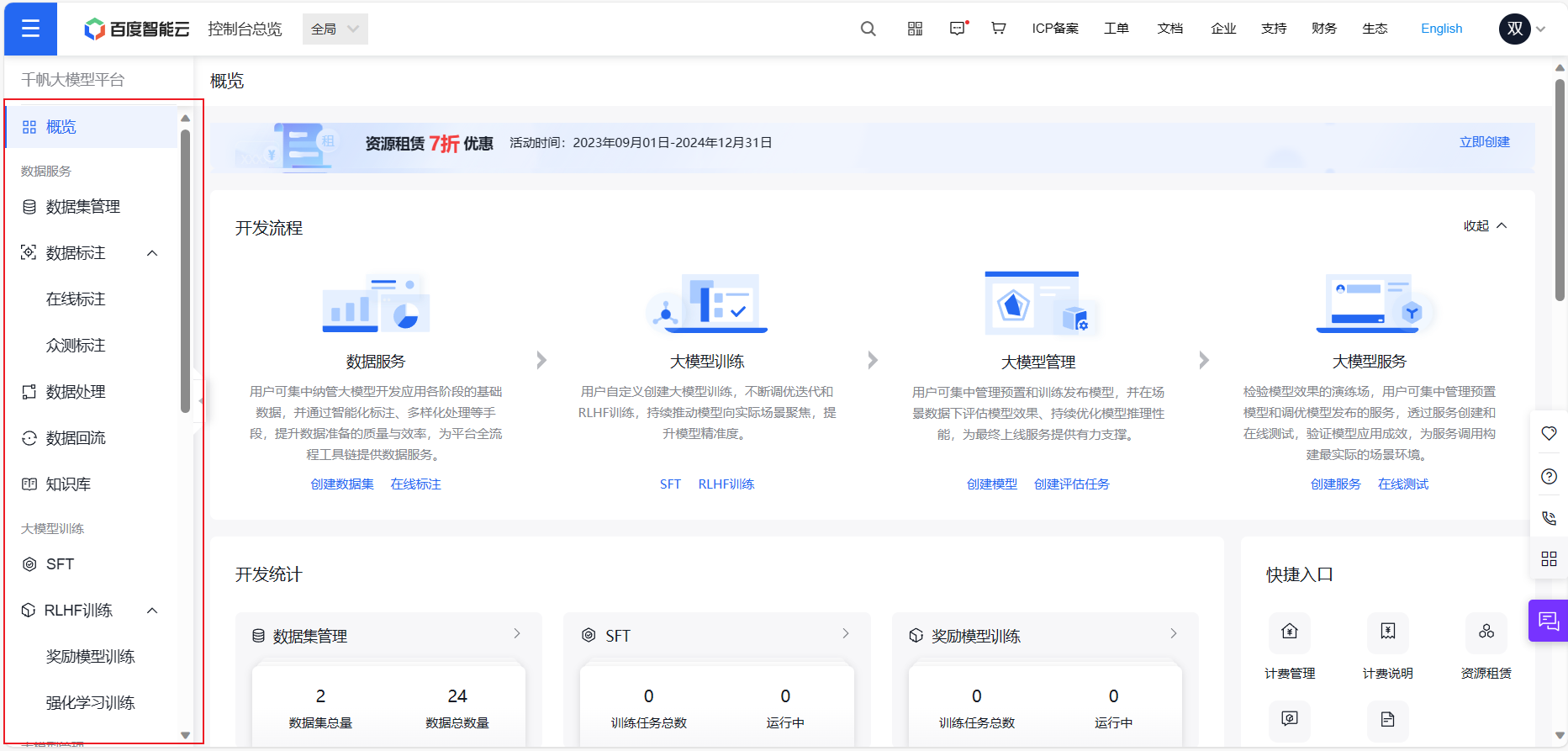
数据集
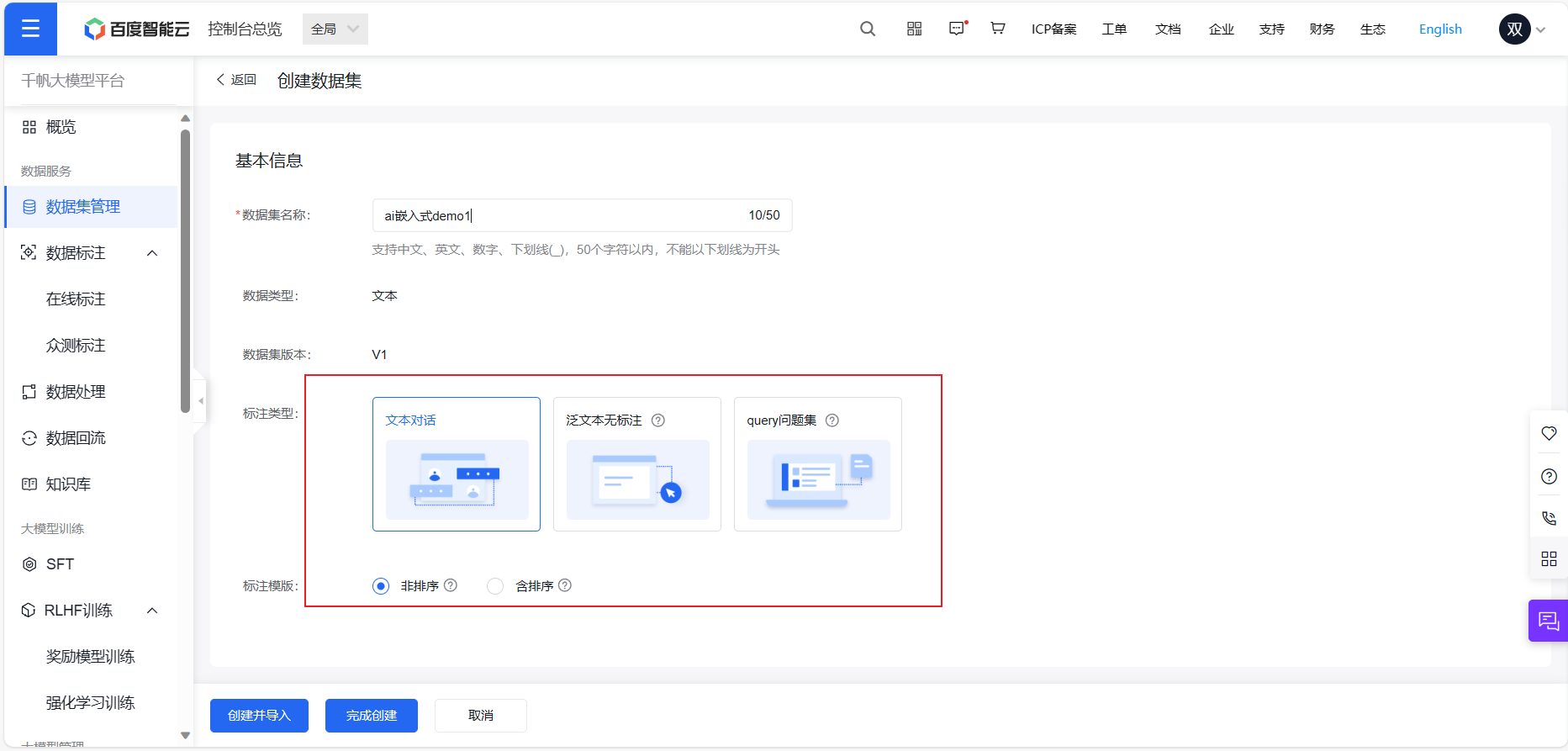
3.1 数据的导入
点击数据集管理,选择创建新的数据集,由于我本人是对ai嵌入式有浓厚兴趣,这次就选用ai嵌入式这个数据集demo,注意选择含排序的数据集,用于RLHF训练,选择非排序的数据集用于SFT训练
3.2 数据标注
数据标注是指对数据集中的每个样本进行标记或注释,以便机器学习算法能够理解和利用这些数据。数据标注通常需要人工介入,将数据集中的每个样本按照一定的标准进行分类、描述或标记。
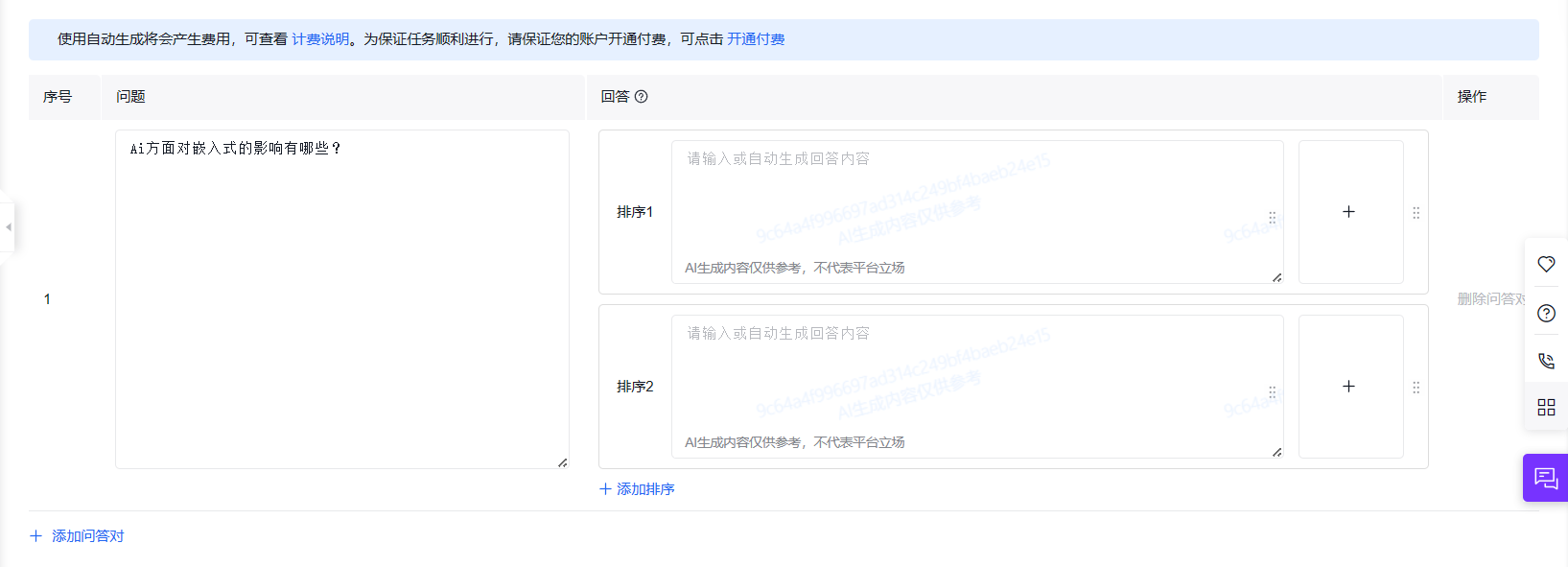
可以选择手动标注或者ai自动标注
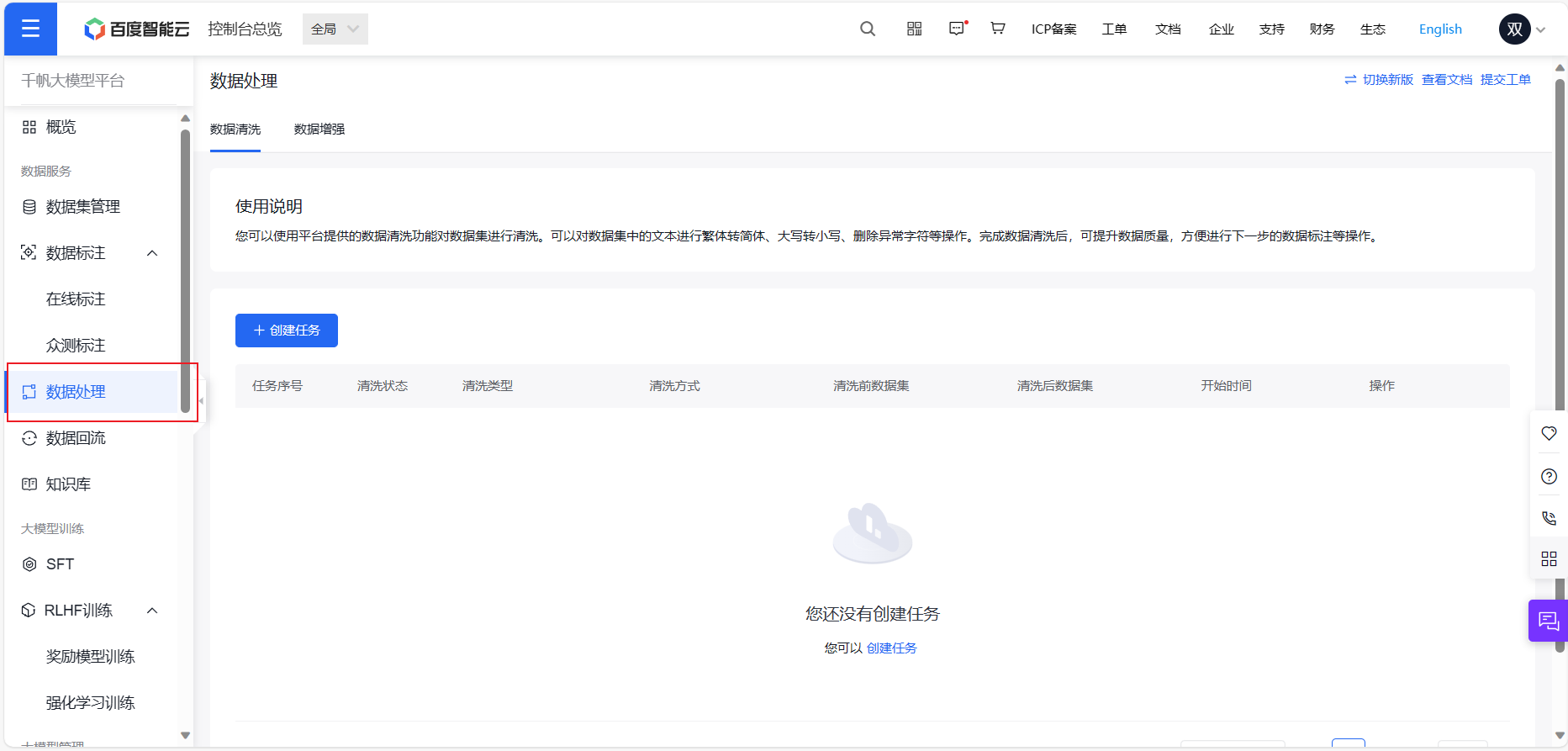
3.3 数据增强或者数据清洗
百度智能云也贴心的为我们提供了傻瓜式的数据增强和数据清洗服务,在数据处理模块里面:
RLHF算法
我这次采用RLHF深度强化学习算法,
RLHF是一种深度强化学习算法,全称为"Reinforcement Learning with Hierarchical Feedback"。它是一种基于分层结构的强化学习算法,旨在解决传统强化学习中面临的稀疏奖励信号、高维状态空间和复杂任务等问题。RLHF算法采用了分层的策略结构,即将任务分解成多个子任务,每个子任务都有自己的奖励信号和策略。同时,RLHF算法还引入了一种称为"层次反馈"的机制,即在每个子任务完成后,将任务的反馈信息传递给上一层任务,以便它可以更好地指导下一层任务的行动。这种层次反馈机制可以有效地加速学习过程,提高算法的效率和性能。与传统的强化学习算法相比,RLHF算法具有以下优点:
先创建奖励模型,然后强化模型需要用到奖励模型。
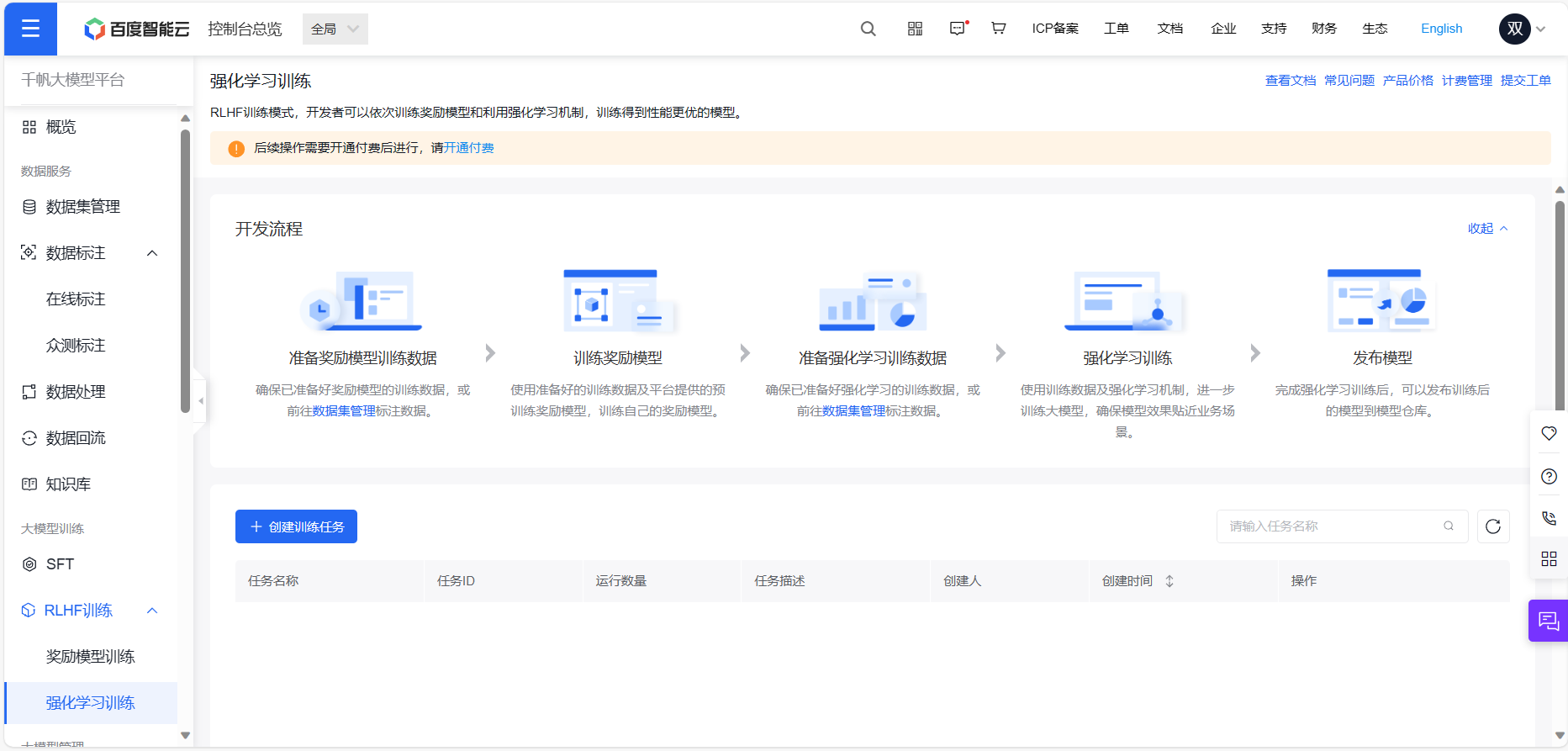
开通付费服务,选择大模型RLHF,操作流程如下图所示:
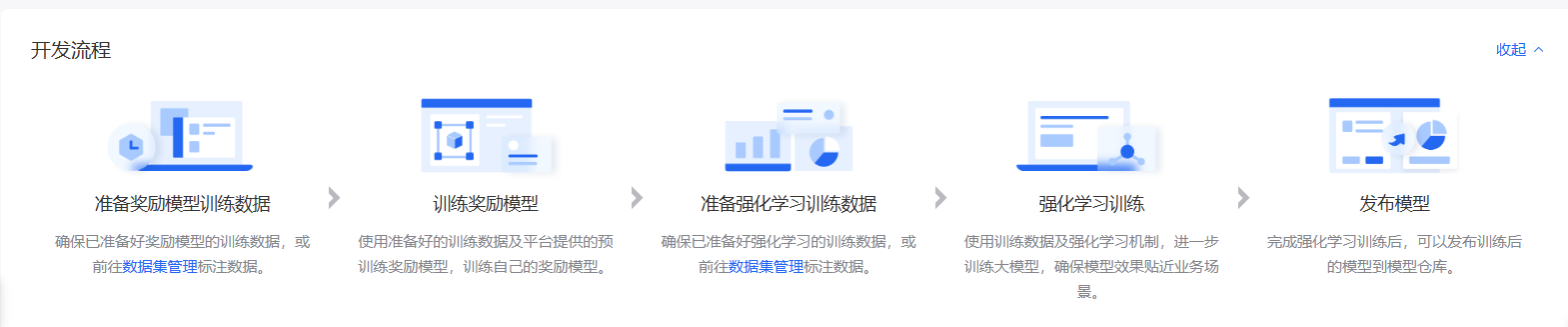
-
创建任务
-
选择上面处理好的数据集对其进行训练
-
然后等运行就好
SFT
SFT(Supervised Fine-Tuning)是一种深度学习中的迁移学习方法,用于将预训练好的神经网络模型应用于新的任务。其原理可以概括为以下几个步骤:
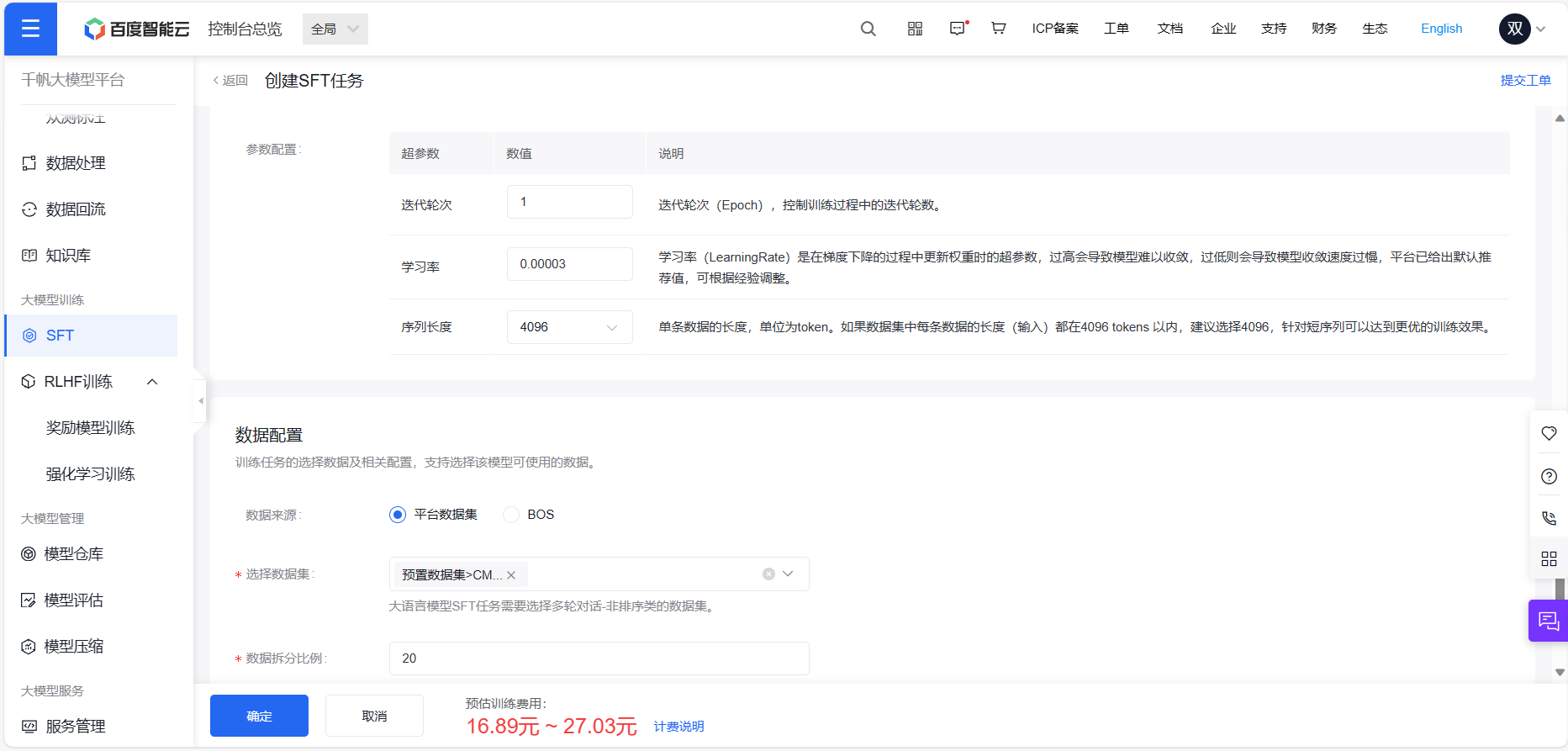
这次的数据集直接采用了百度云的预置数据集。
最后
本次的体验结束,主要还是根据百度智能云的官方文档来进行简单的模型训练和了解国内大模型的应用,总体体验还是比较好的,之后有机会会进行更深层次的应用
评论
