3
使用langchain和文心API打造知识库问答-02知识库问答实现
大模型开发/技术交流
- LLM
- 社区上线
- 开箱评测
2023.09.132749看过
1、前言
1.1、现状
现在的语言大模型(LLM)已经学习了海量知识,对通识性的问答可以说游刃有余;但是比如下面情况:
-
企业内私有的知识,比如某公司的内部培训资料。
-
因为预训练的缘故,时效性比较强的知识内容,比如近期刚发生的新闻。
在回答属于上面等情况的她不知道这类问题时,语言大模型因为不知道,回答时只能瞎编啦。

上面是我们问文心一言:你的训练数据截止到什么时间?她的回复中显示是截止到2021年9月的。
1.2、解决方案
碰到上面的情况,现在的解决方案就是大语言模型+知识库,其中知识库就是使用向量数据库。
关于向量化,请参考我们前一篇使用langchain和文心API打造知识库问答-01文本向量化。
2、实现效果展示
2.1、源数据
我们使用什么是百度智能云千帆大模型平台网页的内容作为源数据。
2.2、提问测试
打开命令行执行python ./qa.py(完整代码下面会提供),显示
请输入问题:
我们先问一下:千帆大模型平台是什么?
千帆大模型平台是面向企业开发者的一站式大模型开发及服务运行平台。百度智能云千帆大模型平台(以下简称千帆或千帆大模型平台)提供了包括文心一言底层模型(ERNIE-Bot)和第三方开源大模型,还提供了各种AI开发工具和整套开发环境,方便客户 轻松使用和开发大模型应用。千帆提供数据管理、自动化模型SFT以及推理服务云端部署的一站式大模型定制服务,助力各行业的生成式AI应用需求落地。
第二个问题:千帆大模型平台有那些应用场景?
千帆大模型平台的应用场景包括对话沟通、内容创作和分析控制。
我们可以对比源数据链接中的内容,这两个问题完全是按照我们提供的文档信息来回答的。
下面我们来看下具体实现过程:
3、知识库问题的实现
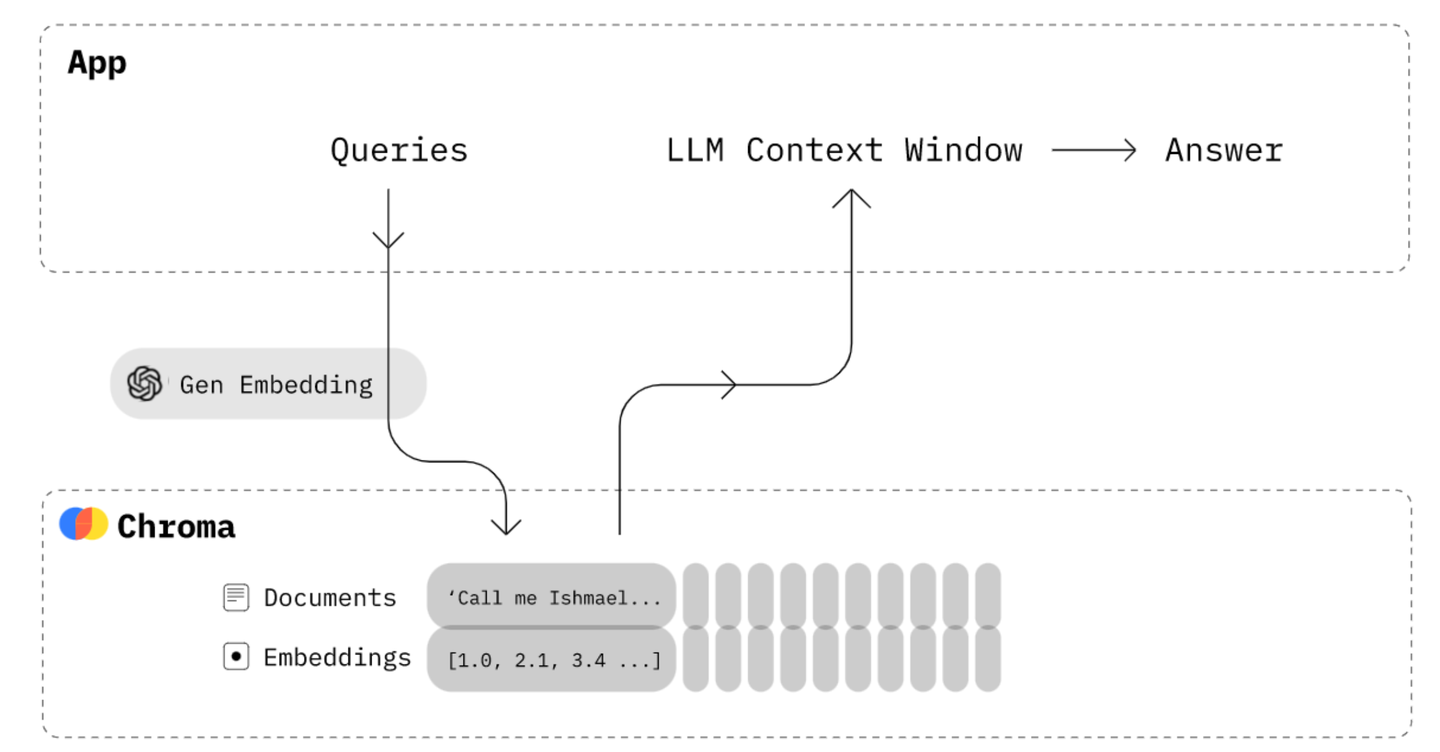
上图是知识库问答应用的整体技术原理图,简单点说就是,先通过问题从向量数据库中查询出相关信息,然后把问题+相关信息一块发给大语言模型,让大语言模型根据提供的信息来回答问题。
具体的步骤可以分为:

3.1、申请key和secret
首先到百度千帆平台<https://cloud.baidu.com/>申请API Key 和 Secret Key。
3.2、安装第三方python库
pip install langchain docx2txt faiss-cpu
3.3、完整代码
程序目录文件说明
documents 源数据目录
qa.py 程序文件(代码下面会提供)
import osimport sysimport timefrom pathlib import Pathimport picklefrom langchain.document_loaders import DirectoryLoader, Docx2txtLoaderfrom langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain.prompts import ChatPromptTemplate, PromptTemplatefrom langchain.chat_models import ErnieBotChatfrom langchain.embeddings import ErnieEmbeddingsfrom langchain.vectorstores import FAISSfrom langchain.schema import format_documentWENXIN_APP_Key = "APP Key"WENXIN_APP_SECRET = "APP Secret"# 本地向量数据库名字VectorStore_Name = 'vs_faiss'# 加载文档def load_documents():# 指定要加载的文档所在目录docx_path = "documents"DOCS_ROOT_PATH = os.path.join(os.path.dirname(os.path.dirname(__file__)), docx_path)# glob指定加载文件类型 .docx# loader_cls指定使用Docx2txtLoader, 就是把docx文件内容转为txt加载loader = DirectoryLoader(DOCS_ROOT_PATH, glob="**/*.docx", loader_cls=Docx2txtLoader, loader_kwargs=None)# 加载文档documents = loader.load()return documents# 分割文档def split_documents(documents):# chunk_size 分割的块大小# chunk_overlap 分割的块重复部分大小,0,# separators 分隔符列表text_splitter = RecursiveCharacterTextSplitter(chunk_size = 380,chunk_overlap = 0,# separators = ["\n\n"],)documents = text_splitter.split_documents(documents)return documents# 文档向量化和存储def embed_documents(documents):embeddings = ErnieEmbeddings(ernie_client_id = WENXIN_APP_Key,ernie_client_secret = WENXIN_APP_SECRET)if not Path(f'{VectorStore_Name}.pkl').exists():# 首次直接从文档创建FAISSprint("create new vectorstore")vectorstore = FAISS.from_documents(documents, embeddings)else:# 非首次从本地加载FAISS, 再添加文档print("load old vectorstore")vectorstore = FAISS.load_local(".", embeddings=embeddings, index_name=VectorStore_Name)vectorstore.add_documents(documents)# 保存到本地vectorstore.save_local(".", index_name=VectorStore_Name)# 提取文档内容向量化def ingest():docs = load_documents()print("load documents length: ", len(docs))docs = split_documents(docs)print("split chunks of document length: ", len(docs))embed_documents(docs)print("completed!")# 格式化documents, 只获取page_contentDEFAULT_DOCUMENT_PROMPT = PromptTemplate.from_template(template="{page_content}")# 合并检索出的文档块def _combine_documents(docs, document_prompt = DEFAULT_DOCUMENT_PROMPT, document_separator="\n\n"):# print(docs)doc_strings = [format_document(doc, document_prompt) for doc in docs]# print(doc_strings)return document_separator.join(doc_strings) if doc_strings else '无相关信息!'# 通过检索进行问答def query(question):embeddings = ErnieEmbeddings(ernie_client_id = WENXIN_APP_Key,ernie_client_secret = WENXIN_APP_SECRET)vectorstore = FAISS.load_local(".", embeddings=embeddings, index_name=VectorStore_Name)# 模板human_template = """你是一个提供问答助手,请使用以下source标签内的信息来回答问题。如果你不知道答案,就说你不知道,不要试图编造答案。<source>{source}</source>问题: {question}回答:"""# 提示prompt = ChatPromptTemplate.from_messages([("human", human_template)])# chatchat_model = ErnieBotChat(ernie_client_id = WENXIN_APP_Key,ernie_client_secret = WENXIN_APP_SECRET)# 创建一个检索器retriever = vectorstore.as_retriever()# 使用langchain expression language(LCEL)构建一个链(chain)full_chain = {"source": (lambda x: x["question"]) | retriever | _combine_documents,"question": lambda x: x["question"],} | prompt | chat_model# 调用链response = full_chain.invoke({"question": question})return responseif __name__ == "__main__":if len(sys.argv) < 2:question = input("请输入问题:")while question:answer = query(question=question)print("回答:\n", answer.content)question = input("请输入问题:")else:operation = sys.argv[1]if operation == "ingest":ingest()else:print("未知操作:", operation)
3.4、提取数据生成向量数据库
我们把什么是百度智能云千帆大模型平台网页的内容保存到documents目录下的新建《什么是百度智能云千帆大模型平台.docx》文件中。
打开命令行执行python ./qa.py ingest,显示
load documents length: 1
split chunks of document length: 3
create new vectorstore
completed!
会自动生成vs_faiss.faiss和vs_faiss.pkl两个文件,这是向量数据库的本地文件。
3.5、测试
参考上面2.2的内容。
4、代码解析
4.1、文档加载
我们定义了load_documents方法来进行文档加载,其中使用了DirectoryLoader这个目录加载器,同时使用了Docx2txtLoader来把对文件实现docx到txt转换。
4.2、分割文档
我们定义了split_documents方法来对加载的文档进行分割,简单来说就是一篇长文档分割成若干文本块(chunk),其中使用了RecursiveCharacterTextSplitter:
-
参数chunk_size指定块的大小,这个参数值参考<https://cloud.baidu.com/doc/WENXINWORKSHOP/s/alj562vvu#body%E5%8F%82%E6%95%B0>中Body参数input的描述。
-
chunk_overlap为0,相邻文本块无重复内容,此参数如果大于0,那么上一个文本块的结尾部分做为下一个文本块的开头。
4.3、向量化和存储
我们定义了split_documents方法来对文本块进行向量化并保存到本地文件,其中我们使用了开源的FAISS(facebook AI Similarity Search的缩写)为向量检索框架。
4.4、检索问答
我们定义了query方法来进行问答,其中主要是构建一个langchain链(chain)来实现的,在构建这个链中,我们使用了langchain expression language(LCEL)来实现,下面代码可以简答理解为:竖线前的输出为竖线后的输入。
full_chain = {"source": (lambda x: x["question"]) | retriever | _combine_documents,"question": lambda x: x["question"],} | prompt | chat_model
-
(lambda x: x["question"])也就是问题传给检索器retriever,检索器从本地根据问题question进行检索获取相关若干文本块
-
获取到的若干文本块传给_combine_documents方法,组装成一个信息内容作为source的参数值
-
source和question两个参数和值传给prompt(使用模板template来实现),组装成相关信息+问题的提问内容
-
把提问内容发给文心大语言模型chat_model
-
这样最后我们使用invoke方法来实现调用,获取返回结果。
3、小结
通过上面代码,我们实现了一个本地知识库的简单问答功能,其中数据源我们只使用了一个word文件作为测试,像pdf,txt,csv,网页等都可以作为数据源。向量数据库我们使用了FAISS,也可以使用Chroma,Milvus,Zilliz(Milvus的在线版本),Supabase (Postgres)等作为向量化检索框架。
喜欢的小伙伴记得使用左边小手点赞!
评论
