18
给文心一言加上知识库和搜索引擎
大模型开发/技术交流
- 文心大模型
- LLM
- 大模型推理
2023.09.089196看过
文心一言开放了,手机端的几个模板还不错
但是还是要拉出来溜溜
待在家里躺床太无聊,所以小小地练练手和脑子
前期准备
申请文心一言apikey
前往并登录 百度智能云-登录 (baidu.com)
创建应用并打开文心一言turbo的付费
然后充值10元钱
创建Milvus数据库(可选)
教程 Install Milvus Standalone with Docker Compose (CPU) Milvus documentation
测试文心一言
首先给langchain安装升 级一下
pip install -U langchain
去langchain库里翻代码找找文心一言的例子
from langchain.chat_models import ErnieBotChatchat = ErnieBotChat(model_name='ERNIE-Bot-turbo',ernie_client_id = 'XXXXXX',ernie_client_secret = 'YYYYYYY',temperature=0.7,)ans = chat.predict("Hello, I'm ErnieBot.")print(ans)
注意client_id应该是你的apikey
成功得到答案
成功得到答案

正式开始
让我们开始我们的敏捷开发
AI应用最快的应用开发方式当然是gradio
我们首先尝试使用gradio调用文心一言
这里要用到gradio的chatbot模块
我们可以直接观赏一下官方用例
chatbot
import gradio as grimport osimport time# Chatbot demo with multimodal input (text, markdown, LaTeX, code blocks, image, audio, & video). Plus shows support for streaming text.def add_text(history, text):history = history + [(text, None)]return history, gr.update(value="", interactive=False)def add_file(history, file):history = history + [((file.name,), None)]return historydef bot(history):response = "**That's cool!**"history[-1][1] = ""for character in response:history[-1][1] += charactertime.sleep(0.05)yield historywith gr.Blocks() as demo:chatbot = gr.Chatbot([],elem_id="chatbot",avatar_images=(None, (os.path.join(os.path.dirname(__file__), "avatar.png"))),)with gr.Row():txt = gr.Textbox(scale=4,show_label=False,placeholder="Enter text and press enter, or upload an image",container=False,)btn = gr.UploadButton("📁", file_types=["image", "video", "audio"])txt_msg = txt.submit(add_text, [chatbot, txt], [chatbot, txt], queue=False).then(bot, chatbot, chatbot)txt_msg.then(lambda: gr.update(interactive=True), None, [txt], queue=False)file_msg = btn.upload(add_file, [chatbot, btn], [chatbot], queue=False).then(bot, chatbot, chatbot)demo.queue()if __name__ == "__main__":demo.launch()
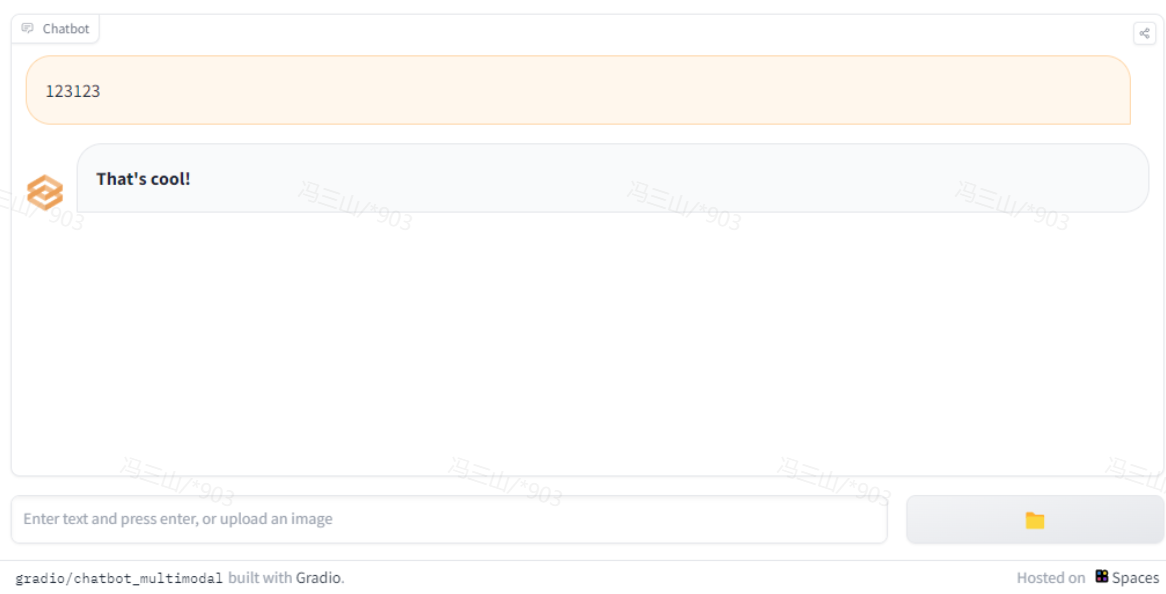
可以看到以下特性
-
聊天框
-
流式传输
-
文件上传
基本满足了一个chatbot的基本需求,我们直接在此基础上进行开发
安装gradio
pip install gradio
观察函数,我们需要修改的地方其实只有response部分
def bot(history):response = "**That's cool!**"history[-1][1] = ""for character in response:history[-1][1] += charactertime.sleep(0.05)yield history
response部分使用文心一言的回答进行替换即可
这里使用了langchain的ConversationChain,并删除了chatbot文件上传功能
import gradio as grimport osimport timefrom langchain.chat_models import ErnieBotChatfrom langchain.chains import ConversationChain###llmchat = ErnieBotChat(model_name='ERNIE-Bot-turbo',ernie_client_id = 'xxxxx',ernie_client_secret = 'yyyyyy',temperature=0.7,)chain = ConversationChain(llm=chat,verbose=True)###gradiodef add_text(history, text):history = history + [(text, None)]return history, gr.update(value="", interactive=False)def bot(history):question = history[-1][0]response = chain.run(question)history[-1][1] = ""for character in response:history[-1][1] += charactertime.sleep(0.05)yield historywith gr.Blocks() as demo:chatbot = gr.Chatbot([],elem_id="chatbot")with gr.Row():txt = gr.Textbox(scale=4,show_label=False,placeholder="Enter text and press enter, or upload an image",container=False,)txt_msg = txt.submit(add_text, [chatbot, txt], [chatbot, txt], queue=False).then(bot, chatbot, chatbot)txt_msg.then(lambda: gr.update(interactive=True), None, [txt], queue=False)demo.queue()if __name__ == "__main__":demo.launch()
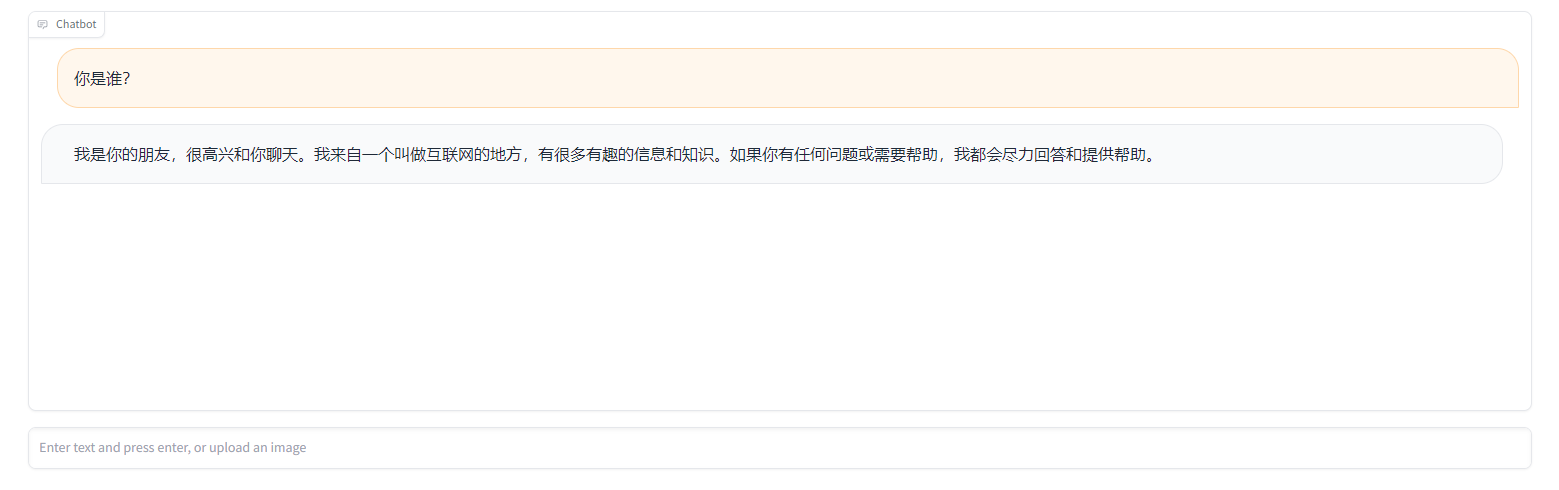
效果不错涅~就是界面有点简陋
接下来我们使用gradio的block功能为我们的界面进行大升级
首先把我们的apikey放到yaml文件中
pip install pyyaml
添加的代码如下
import yaml###llmwith open("new_cof.yaml", "r", encoding="utf-8") as f:config = yaml.load(f, Loader=yaml.FullLoader)llm_model = config["MODELS"]["llm_model"]embedding_model = config["MODELS"]["embedding_model"]ernie_client_id = config["API"]["ernie_client_id"]ernie_client_secret = config["API"]["ernie_client_secret"]
yaml文件,
new_cof.yaml
API:ernie_client_id: xxxxxxernie_client_secret: yyyyopenai_api_key: zzzzzMODELS:llm_model:- Ernie- OpenAIembedding_model:- Ernie- OpenAIblock:concurrency_count: 32server_name: "0.0.0.0"server_port: 7860debug: true
添加个初始化模型和chain的函数
def init_model(llm_model_name,embedding_model_name,temperature,max_tokens):llm_model = ErnieBotChat(ernie_client_id = ernie_client_id,ernie_client_secret = ernie_client_secret,temperature=temperature,)embedding_model = ErnieEmbeddings(ernie_client_id = ernie_client_id,ernie_client_secret = ernie_client_secret,)return llm_model,embedding_modeldef init_base_chain(llm_model,history,user_question=None):chain = ConversationChain(llm=llm_model,verbose=True,memory=history,)try:output = chain.run(user_question)except Exception as e:raise ereturn output
通过gradio的block函数优化我们的设计
###gradioblock = gr.Blocks(css="footer {visibility: hidden}",title="文言一心助手")with block:history = ConversationBufferMemory() #历史记录history_state = gr.State(history) #历史记录的状态llm_model_state = gr.State() #llm模型的状态embedding_model_state = gr.State() #embedding模型的状态trash = gr.State() #垃圾桶with gr.Row():#设置行with gr.Column(scale=1):with gr.Accordion("模型配置", open=False):llm_model_name = gr.Dropdown(choices=llm_model, value=llm_model[0], label="语言模型",multiselect=False,interactive=True)embedding_model_name = gr.Dropdown(choices=embedding_model, value=embedding_model[0], label="embedding模型",multiselect=False,interactive=True)temperature = gr.Slider(minimum=0.0,maximum=1.0,value=0.7,step=0.1,label="temperature",interactive=True,)max_tokens = gr.Slider(minimum=1,maximum=16384,value=1000,step=1,label="max_tokens",interactive=True,)modle_settings = gr.Button("应用")with gr.Column(scale=4):chatbot = gr.Chatbot(label="文心酱")with gr.Row():message = gr.Textbox(label="在此处填写你的问题",placeholder="我有很多问题想问你......",lines=1,)with gr.Row():submit = gr.Button("发送", variant="primary")#刷新clear = gr.Button("刷新", variant="secondary")def clear_():chatbot = []history_state = ConversationBufferMemory()return "", chatbot, history_statedef user(user_message, history):return "",history + [[user_message, None]]def bot(user_message,chatbot = None,history_state = ConversationBufferMemory(),temperature = None,max_tokens = None,llm_model=None,embedding_model=None,llm_model_name = None,embedding_model_name = None):try:user_message = chatbot[-1][0]if llm_model is None or embedding_model is None:llm_model,embedding_model = init_model(llm_model_name,embedding_model_name,temperature,max_tokens)output = init_base_chain(llm_model,history=history_state,user_question=user_message)except Exception as e:raise echatbot[-1][1] = ""for character in output:chatbot[-1][1] += charactertime.sleep(0.03)yield chatbot#刷新按钮clear.click(clear_, inputs=[], outputs=[message, chatbot, history_state])#send按钮submit.click(user, [message, chatbot], [message,chatbot], queue=False).then(bot, [message,chatbot,history_state,temperature,max_tokens,llm_model_state,embedding_model_state,llm_model_name,embedding_model_name], [chatbot])#回车message.submit(user, [message, chatbot], [message,chatbot], queue=False).then(bot, [message,chatbot,history_state,temperature,max_tokens,llm_model_state,embedding_model_state,llm_model_name,embedding_model_name], [chatbot])# 启动参数block.queue(concurrency_count=config['block']['concurrency_count']).launch(debug=config['block']['debug'],server_name=config['block']['server_name'],server_port=config['block']['server_port'],)
启动后项目界面如下
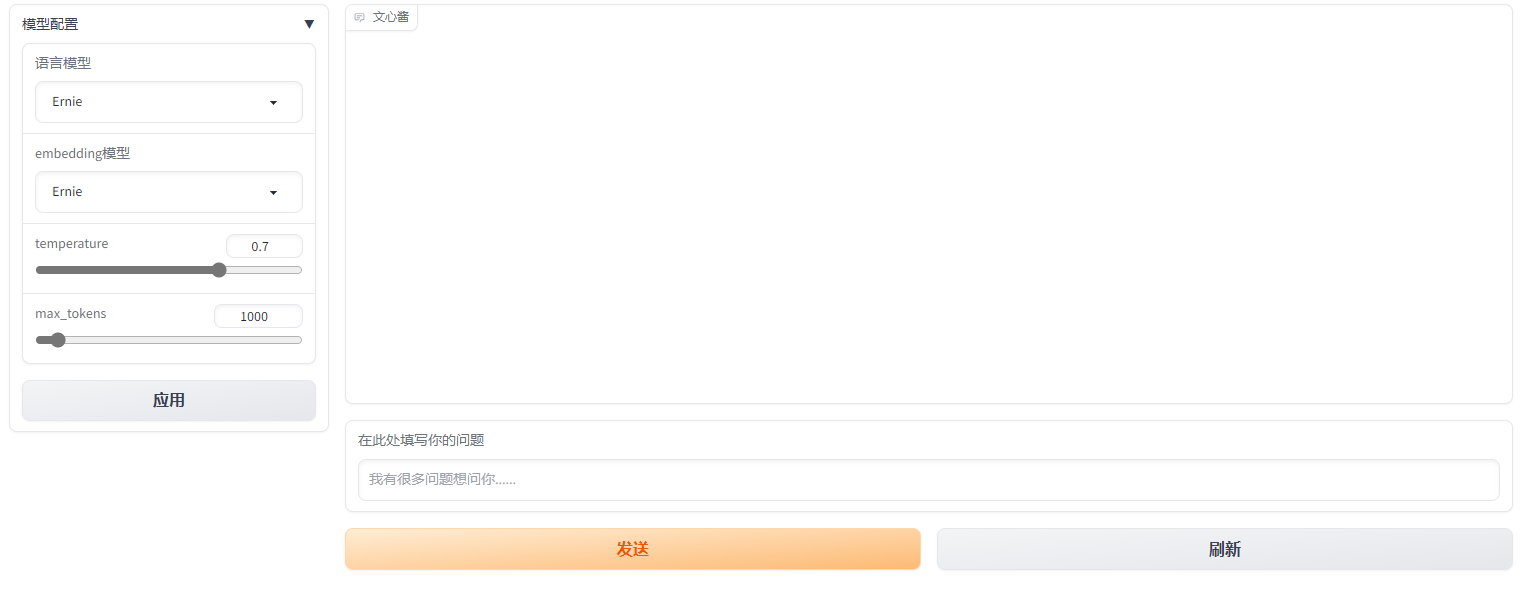
来感觉了,有没有
来试试
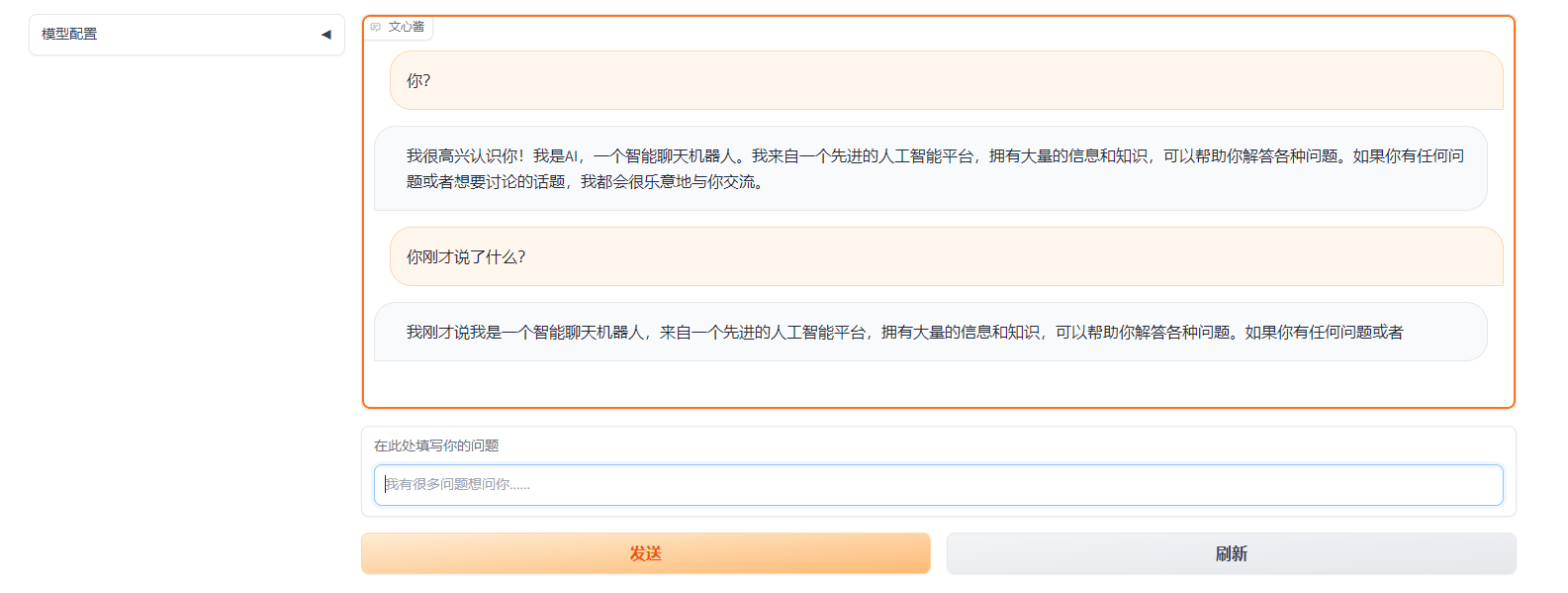
可以看到我们目前实现的功能设计:
-
流式回答
-
上下文记忆
-
刷新与发送
-
更改模型配置
至此一个完整简单的chatbot设计就完成了
Embedding
我们在使用embedding功能时主要用到了milvus向量数据库,也有平替的向量数据库,请自行寻找...
设计gradio切换embedding和llm的按钮,来决定是否使用知识库
并设计按钮使用知识库
with gr.Accordion("知识库选项", open=False):with gr.Tab("上传"):file = gr.File(label='上传知识库文件',file_types=['.txt', '.md', '.docx', '.pdf','.pptx','.epub','.xlsx'])init_dataset_upload = gr.Button("应用")with gr.Tab("链接载入"):knowledge_url_box = gr.Textbox(label="url载入知识库",placeholder="请粘贴你的知识库url",show_label=True,lines=1)init_dataset_url = gr.Button("应用")
为知识库添加支持函数,并使用embedding相关的chain
def sheet_to_string(sheet, sheet_name = None):result = []for index, row in sheet.iterrows():row_string = ""for column in sheet.columns:row_string += f"{column}: {row[column]}, "row_string = row_string.rstrip(", ")row_string += "."result.append(row_string)return resultdef excel_to_string(file_path):# 读取Excel文件中的所有工作表excel_file = pd.read_excel(file_path, engine='openpyxl', sheet_name=None)# 初始化结果字符串result = []# 遍历每一个工作表for sheet_name, sheet_data in excel_file.items():# 处理当前工作表并添加到结果字符串result += sheet_to_string(sheet_data, sheet_name=sheet_name)return resultdef get_documents(file_src):from langchain.schema import Documentfrom langchain.text_splitter import TokenTextSplittertext_splitter = TokenTextSplitter(chunk_size=500, chunk_overlap=30)documents = []for file in file_src:filepath = file.namefilename = os.path.basename(filepath)file_type = os.path.splitext(filename)[1]try:if file_type == ".pdf":pdftext = ""with open(filepath, "rb") as pdfFileObj:pdfReader = PyPDF2.PdfReader(pdfFileObj)for page in tqdm(pdfReader.pages):pdftext += page.extract_text()texts = [Document(page_content=pdftext,metadata={"source": filepath})]elif file_type == ".docx":from langchain.document_loaders import UnstructuredWordDocumentLoaderloader = UnstructuredWordDocumentLoader(filepath)texts = loader.load()elif file_type == ".pptx":from langchain.document_loaders import UnstructuredPowerPointLoaderloader = UnstructuredPowerPointLoader(filepath)texts = loader.load()elif file_type == ".epub":from langchain.document_loaders import UnstructuredEPubLoaderloader = UnstructuredEPubLoader(filepath)texts = loader.load()elif file_type == ".xlsx":text_list = excel_to_string(filepath)texts = []for elem in text_list:texts.append(Document(page_content=elem,metadata={"source": filepath}))else:from langchain.document_loaders import TextLoaderloader = TextLoader(filepath, "utf8")texts = loader.load()except Exception as e:raise etexts = text_splitter.split_documents(texts)documents.extend(texts)return documentsdef load_embedding_chain_file(fileobj=None,embedding_model=None):if fileobj:filepath = fileobj.nameprint(filepath)bookname = f"temp{uuid4()}"#docs = load_file(filepath)docs = get_documents([fileobj])vectorDB = Milvus.from_documents(docs,embedding_model,connection_args={"host": MILVUS_HOST,"port": MILVUS_PORT},collection_name = bookname,drop_old = True #是否删除旧的collection)return vectorDB,booknamedef load_embedding_chain_url(url=None,embedding_model=None):if url:filepath = urlprint(filepath)bookname = f"temp{uuid4()}"docs = get_documents([url])vectorDB = Milvus.from_documents(docs,embedding_model,connection_args={"host": MILVUS_HOST,"port": MILVUS_PORT},collection_name = bookname,drop_old = True #是否删除旧的collection)return vectorDB,bookname
重写block部分和部分函数,添加知识库支持,这是目前的完整函数
import gradio as grimport osimport timefrom langchain.chat_models import ErnieBotChatfrom langchain.chains import ConversationChainfrom langchain.memory import ConversationBufferMemoryfrom langchain.embeddings import ErnieEmbeddingsimport yamlimport randomimport pandas as pdimport PyPDF2from tqdm import tqdmfrom langchain.vectorstores import Milvusfrom langchain.prompts import PromptTemplatefrom langchain.chains import RetrievalQA###llmwith open("new_cof.yaml", "r", encoding="utf-8") as f:config = yaml.load(f, Loader=yaml.FullLoader)llm_model = config["MODELS"]["llm_model"]embedding_model = config["MODELS"]["embedding_model"]ernie_client_id = config["API"]["ernie_client_id"]ernie_client_secret = config["API"]["ernie_client_secret"]openai_api_key = config["API"]["openai_api_key"]MILVUS_HOST = config["MILVUS"]["host"]MILVUS_PORT = config["MILVUS"]["port"]def pre_embeding_file(chatbot):message = "预热知识库中,请耐心等待完成......"return chatbot + [[message, None]]def applydata_(chatbot):message = "载入知识库成功"return chatbot + [[message, None]]def is_use_database(chatbot,use_database):if use_database == "是":message = "使用知识库中...."else:message = "取消使用知识库"return chatbot + [[message, None]]def apply_model_setting(model_name, embedding_model_name,chatbot):message = f"载入语言模型{model_name},embedding模型{embedding_model_name}"return chatbot + [[message, None]]def init_model(llm_model_name,embedding_model_name,temperature,max_tokens):llm_model = ErnieBotChat(ernie_client_id = ernie_client_id,ernie_client_secret = ernie_client_secret,temperature=temperature,)embedding_model = ErnieEmbeddings(ernie_client_id = ernie_client_id,ernie_client_secret = ernie_client_secret,)return llm_model,embedding_modeldef general_template(history=False):general_template = f"""这下面是文心酱AI与人类的对话. The AI is talkative and provides lots of specific details from its context. 如果AI不知道问题的答案,AI会诚实地说"我不知道",而不是编造一个答案。AI在回答问题会注意自己的身份和角度。----Current conversation:"""if history:general_template += """{history}"""general_template += """Human: {input}AI: """else:general_template += """已知内容:'''{context}'''"""general_template += """Human: {question}AI: """return general_templatedef init_base_chain(llm_model,history = None,user_question = None):template = general_template(history=True)chain = ConversationChain(llm=llm_model,verbose=True,memory=history,)chain.prompt.template = templatetry:output = chain.run(user_question)except Exception as e:raise ereturn outputdef init_base_embedding_chain(llm_model,embedding_model,knowledge_database,user_question):if knowledge_database:template = general_template()QA_CHAIN_PROMPT = PromptTemplate.from_template(template)vectorDB = Milvus(embedding_model,connection_args= {"host": MILVUS_HOST,"port": MILVUS_PORT},collection_name = knowledge_database,)qa_chain = RetrievalQA.from_chain_type(llm = llm_model,chain_type="stuff",retriever=vectorDB.as_retriever(),chain_type_kwargs={"prompt": QA_CHAIN_PROMPT,"verbose":True})try:output = qa_chain.run(user_question)except Exception as e:raise ereturn outputdef sheet_to_string(sheet, sheet_name = None):result = []for index, row in sheet.iterrows():row_string = ""for column in sheet.columns:row_string += f"{column}: {row[column]}, "row_string = row_string.rstrip(", ")row_string += "."result.append(row_string)return resultdef excel_to_string(file_path):# 读取Excel文件中的所有工作表excel_file = pd.read_excel(file_path, engine='openpyxl', sheet_name=None)# 初始化结果字符串result = []# 遍历每一个工作表for sheet_name, sheet_data in excel_file.items():# 处理当前工作表并添加到结果字符串result += sheet_to_string(sheet_data, sheet_name=sheet_name)return resultdef get_documents(file_src):from langchain.schema import Documentfrom langchain.text_splitter import TokenTextSplittertext_splitter = TokenTextSplitter(chunk_size=500, chunk_overlap=30)documents = []for file in file_src:filepath = file.namefilename = os.path.basename(filepath)file_type = os.path.splitext(filename)[1]try:if file_type == ".pdf":pdftext = ""with open(filepath, "rb") as pdfFileObj:pdfReader = PyPDF2.PdfReader(pdfFileObj)for page in tqdm(pdfReader.pages):pdftext += page.extract_text()texts = [Document(page_content=pdftext,metadata={"source": filepath})]elif file_type == ".docx":from langchain.document_loaders import UnstructuredWordDocumentLoaderloader = UnstructuredWordDocumentLoader(filepath)texts = loader.load()elif file_type == ".pptx":from langchain.document_loaders import UnstructuredPowerPointLoaderloader = UnstructuredPowerPointLoader(filepath)texts = loader.load()elif file_type == ".epub":from langchain.document_loaders import UnstructuredEPubLoaderloader = UnstructuredEPubLoader(filepath)texts = loader.load()elif file_type == ".xlsx":text_list = excel_to_string(filepath)texts = []for elem in text_list:texts.append(Document(page_content=elem,metadata={"source": filepath}))else:from langchain.document_loaders import TextLoaderloader = TextLoader(filepath, "utf8")texts = loader.load()except Exception as e:raise etexts = text_splitter.split_documents(texts)documents.extend(texts)return documentsdef load_embedding_chain_file(fileobj=None,embedding_model=None):if embedding_model is None:llm_model,embedding_model = init_model(llm_model_name = None,embedding_model_name = None ,temperature = 0.7,max_tokens = 2000)if fileobj:filepath = fileobj.nameprint(filepath)bookname = f"temp{random.randint(0,100000)}"docs = get_documents([fileobj])vectorDB = Milvus.from_documents(docs,embedding_model,connection_args={"host": MILVUS_HOST,"port": MILVUS_PORT},collection_name = bookname,drop_old = True #是否删除旧的collection)return vectorDB,booknamedef load_embedding_chain_url(url=None,embedding_model=None):if embedding_model is None:llm_model,embedding_model = init_model(llm_model_name = None,embedding_model_name = None ,temperature = 0.7,max_tokens = 2000)if url:filepath = urlprint(filepath)bookname = f"temp{random.randint(0,100000)}"docs = get_documents([url])vectorDB = Milvus.from_documents(docs,embedding_model,connection_args={"host": MILVUS_HOST,"port": MILVUS_PORT},collection_name = bookname,drop_old = True #是否删除旧的collection)return vectorDB,bookname###gradioblock = gr.Blocks(css="footer {visibility: hidden}",title="文言一心助手")with block:history = ConversationBufferMemory()history_state = gr.State(history) #历史记录的状态llm_model_state = gr.State() #llm模型的状态embedding_model_state = gr.State() #embedding模型的状态milvus_books = Nonemilvus_books_state = gr.State(milvus_books) #milvus_books的状态trash = gr.State() #垃圾桶with gr.Row():#设置行with gr.Column(scale=1):with gr.Accordion("模型配置", open=False):llm_model_name = gr.Dropdown(choices=llm_model, value=llm_model[0], label="语言模型",multiselect=False,interactive=True)embedding_model_name = gr.Dropdown(choices=embedding_model, value=embedding_model[0], label="embedding模型",multiselect=False,interactive=True)temperature = gr.Slider(minimum=0.0,maximum=1.0,value=0.7,step=0.1,label="temperature",interactive=True,)max_tokens = gr.Slider(minimum=1,maximum=16384,value=1000,step=1,label="max_tokens",interactive=True,)modle_settings = gr.Button("应用")use_database = gr.Radio(["是", "否"],label="是否使用知识库",value="否")with gr.Accordion("知识库选项", open=False):with gr.Tab("上传"):file = gr.File(label='上传知识库文件',file_types=['.txt', '.md', '.docx', '.pdf','.pptx','.epub','.xlsx'])init_dataset_upload = gr.Button("应用")with gr.Tab("链接载入"):knowledge_url_box = gr.Textbox(label="url载入知识库",placeholder="请粘贴你的知识库url",show_label=True,lines=1)init_dataset_url = gr.Button("应用")with gr.Column(scale=4):chatbot = gr.Chatbot(label="文心酱")with gr.Row():message = gr.Textbox(label="在此处填写你的问题",placeholder="我有很多问题想问你......",lines=1,)with gr.Row():submit = gr.Button("发送", variant="primary")#刷新clear = gr.Button("刷新", variant="secondary")def clear_():chatbot = []history_state = ConversationBufferMemory()return "", chatbot, history_statedef user(user_message, history):return "",history + [[user_message, None]]def bot(user_message,chatbot = None,history_state = ConversationBufferMemory(),temperature = None,max_tokens = None,llm_model=None,embedding_model=None,llm_model_name = None,embedding_model_name = None,use_database = None,milvus_books_state = None):try:user_message = chatbot[-1][0]if llm_model is None or embedding_model is None:llm_model,embedding_model = init_model(llm_model_name,embedding_model_name,temperature,max_tokens)if use_database == "否":output = init_base_chain(llm_model,history=history_state,user_question=user_message)else:output = init_base_embedding_chain(llm_model,embedding_model,milvus_books_state,user_question=user_message)except Exception as e:raise echatbot[-1][1] = ""for character in output:chatbot[-1][1] += charactertime.sleep(0.03)yield chatbot#是否使用知识库use_database.change(is_use_database, inputs=[chatbot,use_database], outputs=[chatbot])#模型配置modle_settings.click(init_model, inputs=[llm_model_name,embedding_model_name,temperature,max_tokens], outputs=[llm_model_state,embedding_model_state]).then(apply_model_setting, inputs=[llm_model_name,embedding_model_name,chatbot], outputs=[chatbot])#知识库选项init_dataset_upload.click(pre_embeding_file,inputs=[chatbot],outputs=[chatbot]).then(load_embedding_chain_file, inputs=[file,embedding_model_state], outputs=[trash,milvus_books_state]).then(applydata_, inputs=[chatbot], outputs=[chatbot])init_dataset_url.click(pre_embeding_file,inputs=[chatbot],outputs=[chatbot]).then(load_embedding_chain_url, inputs=[knowledge_url_box,embedding_model_state], outputs=[trash,milvus_books_state]).then(applydata_, inputs=[chatbot], outputs=[chatbot])#刷新按钮clear.click(clear_, inputs=[], outputs=[message, chatbot, history_state])#send按钮submit.click(user, [message, chatbot], [message,chatbot], queue=False).then(bot, [message,chatbot,history_state,temperature,max_tokens,llm_model_state,embedding_model_state,llm_model_name,embedding_model_name,use_database,milvus_books_state], [chatbot])#回车message.submit(user, [message, chatbot], [message,chatbot], queue=False).then(bot, [message,chatbot,history_state,temperature,max_tokens,llm_model_state,embedding_model_state,llm_model_name,embedding_model_name,use_database,milvus_books_state], [chatbot])# 启动参数block.queue(concurrency_count=config['block']['concurrency_count']).launch(debug=config['block']['debug'],server_name=config['block']['server_name'],server_port=config['block']['server_port'],)
界面
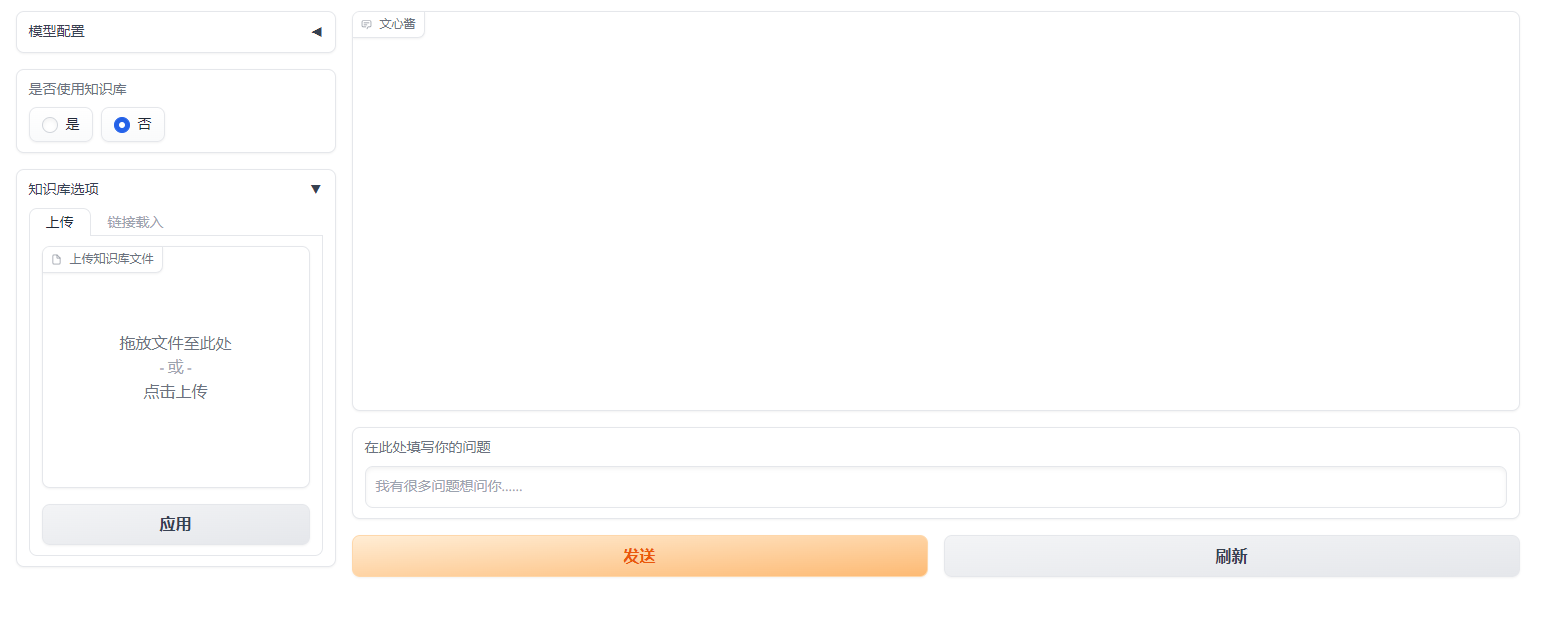
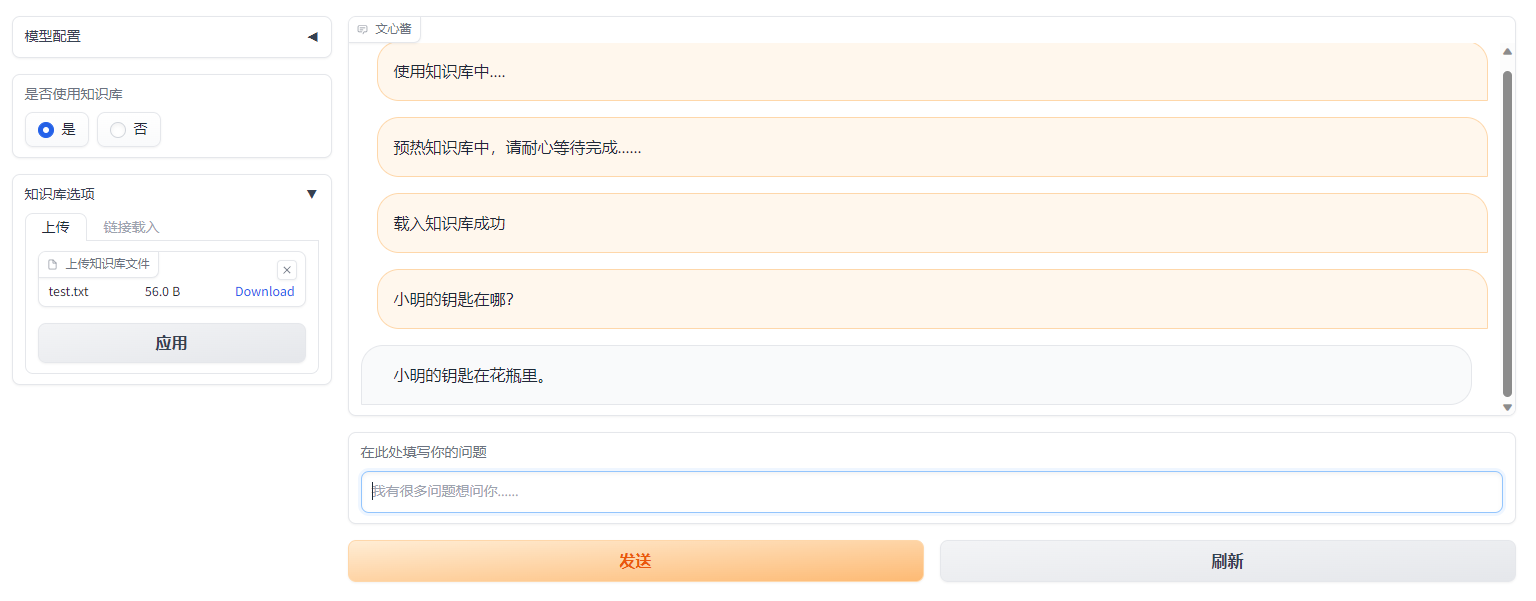
使用,从文本中测试
新建文本文件test.txt
小明的钥匙在花瓶里小红的钥匙在门垫下
选择载入知识库,并上传test.txt
询问问题,可以看到我们的知识库完美实现了功能
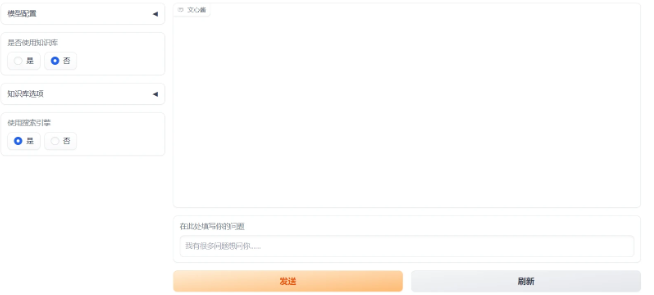
目前为止,我们实现的功能有
-
上传文件作为知识库
-
从链接中载入知识库
-
是否使用知识库的切换
search
这里我们使用了duckduckgo_search作为我们的搜索引擎,如果你愿意,使用百度微软谷歌也是同理
pip install -U duckduckgo_search
搜索实现
from duckduckgo_search import DDGSimport itertoolsdef ddg_search(tosearch):web_content = ""count = 1with DDGS(timeout=10) as ddgs:answer = itertools.islice(ddgs.text(f"{tosearch}",region="cn-zh"), 5)#for result in answer:web_content += f"{count}. {result['body']}"count += 1# instant = itertools.islice(ddgs.answers(f"kingsoft"), 5)#,region="cn-zh"# for result in instant:# web_content += f"{count}. {result['text']}\n"return web_content
让我们把搜索加入我们的应用
import gradio as grimport osimport timefrom langchain.chat_models import ErnieBotChatfrom langchain.chains import ConversationChainfrom langchain.memory import ConversationBufferMemoryfrom langchain.embeddings import ErnieEmbeddingsimport yamlimport randomimport pandas as pdimport PyPDF2from tqdm import tqdmfrom langchain.vectorstores import Milvusfrom langchain.prompts import PromptTemplatefrom langchain.chains import RetrievalQAfrom duckduckgo_search import DDGSimport itertools###llmdef ddg_search(tosearch):web_content = ""count = 1with DDGS(timeout=10) as ddgs:answer = itertools.islice(ddgs.text(f"{tosearch}",region="cn-zh"), 5)#for result in answer:web_content += f"{count}. {result['body']}"count += 1# instant = itertools.islice(ddgs.answers(f"kingsoft"), 5)#,region="cn-zh"# for result in instant:# web_content += f"{count}. {result['text']}\n"return web_contentwith open("new_cof.yaml", "r", encoding="utf-8") as f:config = yaml.load(f, Loader=yaml.FullLoader)llm_model = config["MODELS"]["llm_model"]embedding_model = config["MODELS"]["embedding_model"]ernie_client_id = config["API"]["ernie_client_id"]ernie_client_secret = config["API"]["ernie_client_secret"]openai_api_key = config["API"]["openai_api_key"]MILVUS_HOST = config["MILVUS"]["host"]MILVUS_PORT = config["MILVUS"]["port"]def pre_embeding_file(chatbot):message = "预热知识库中,请耐心等待完成......"return chatbot + [[message, None]]def applydata_(chatbot):message = "载入知识库成功"return chatbot + [[message, None]]def is_use_database(chatbot,use_database):if use_database == "是":message = "使用知识库中...."else:message = "取消使用知识库"return chatbot + [[message, None]]def is_use_web(chatbot,use_web):if use_web == "是":print(use_web)message = "使用搜索引擎中...."else:message = "取消使用搜索引擎"return chatbot + [[message, None]]def apply_model_setting(model_name, embedding_model_name,chatbot):message = f"载入语言模型{model_name},embedding模型{embedding_model_name}"return chatbot + [[message, None]]def init_model(llm_model_name,embedding_model_name,temperature,max_tokens):llm_model = ErnieBotChat(ernie_client_id = ernie_client_id,ernie_client_secret = ernie_client_secret,temperature=temperature,)embedding_model = ErnieEmbeddings(ernie_client_id = ernie_client_id,ernie_client_secret = ernie_client_secret,)return llm_model,embedding_modeldef base_general_template(history=False,question=None):general_template = f"""这下面是文心酱AI与人类的对话. The AI is talkative and provides lots of specific details from its context. 如果AI不知道问题的答案,AI会诚实地说"我不知道",而不是编造一个答案。AI在回答问题会注意自己的身份和角度。"""if question:webcontent = ddg_search(question)if webcontent:general_template += f"""已知网络检索内容:{webcontent}"""general_template += """----Current conversation:"""if history:general_template += """{history}"""general_template += """Human: {input}AI: """else:general_template += """已知内容:'''{context}'''"""general_template += """Human: {question}AI: """return general_templatedef init_base_chain(llm_model,history = None,user_question = None,use_search_engine = False):if use_search_engine == "是":template = base_general_template(history=True,question=user_question)else:template = base_general_template(history=True,question=None)chain = ConversationChain(llm=llm_model,verbose=True,memory=history,)chain.prompt.template = templatetry:output = chain.run(user_question)except Exception as e:raise ereturn outputdef init_base_embedding_chain(llm_model,embedding_model,knowledge_database,user_question,use_search_engine = False):if knowledge_database:if use_search_engine == "是":template = base_general_template(history=False,question=user_question)else:template = base_general_template(history=False,question=None)QA_CHAIN_PROMPT = PromptTemplate.from_template(template)vectorDB = Milvus(embedding_model,connection_args= {"host": MILVUS_HOST,"port": MILVUS_PORT},collection_name = knowledge_database,)qa_chain = RetrievalQA.from_chain_type(llm = llm_model,chain_type="stuff",retriever=vectorDB.as_retriever(),chain_type_kwargs={"prompt": QA_CHAIN_PROMPT,"verbose":True})try:output = qa_chain.run(user_question)except Exception as e:raise ereturn outputdef sheet_to_string(sheet, sheet_name = None):result = []for index, row in sheet.iterrows():row_string = ""for column in sheet.columns:row_string += f"{column}: {row[column]}, "row_string = row_string.rstrip(", ")row_string += "."result.append(row_string)return resultdef excel_to_string(file_path):# 读取Excel文件中的所有工作表excel_file = pd.read_excel(file_path, engine='openpyxl', sheet_name=None)# 初始化结果字符串result = []# 遍历每一个工作表for sheet_name, sheet_data in excel_file.items():# 处理当前工作表并添加到结果字符串result += sheet_to_string(sheet_data, sheet_name=sheet_name)return resultdef get_documents(file_src):from langchain.schema import Documentfrom langchain.text_splitter import TokenTextSplittertext_splitter = TokenTextSplitter(chunk_size=500, chunk_overlap=30)documents = []for file in file_src:filepath = file.namefilename = os.path.basename(filepath)file_type = os.path.splitext(filename)[1]try:if file_type == ".pdf":pdftext = ""with open(filepath, "rb") as pdfFileObj:pdfReader = PyPDF2.PdfReader(pdfFileObj)for page in tqdm(pdfReader.pages):pdftext += page.extract_text()texts = [Document(page_content=pdftext,metadata={"source": filepath})]elif file_type == ".docx":from langchain.document_loaders import UnstructuredWordDocumentLoaderloader = UnstructuredWordDocumentLoader(filepath)texts = loader.load()elif file_type == ".pptx":from langchain.document_loaders import UnstructuredPowerPointLoaderloader = UnstructuredPowerPointLoader(filepath)texts = loader.load()elif file_type == ".epub":from langchain.document_loaders import UnstructuredEPubLoaderloader = UnstructuredEPubLoader(filepath)texts = loader.load()elif file_type == ".xlsx":text_list = excel_to_string(filepath)texts = []for elem in text_list:texts.append(Document(page_content=elem,metadata={"source": filepath}))else:from langchain.document_loaders import TextLoaderloader = TextLoader(filepath, "utf8")texts = loader.load()except Exception as e:raise etexts = text_splitter.split_documents(texts)documents.extend(texts)return documentsdef load_embedding_chain_file(fileobj=None,embedding_model=None):if embedding_model is None:llm_model,embedding_model = init_model(llm_model_name = None,embedding_model_name = None ,temperature = 0.7,max_tokens = 2000)if fileobj:filepath = fileobj.nameprint(filepath)bookname = f"temp{random.randint(0,100000)}"docs = get_documents([fileobj])vectorDB = Milvus.from_documents(docs,embedding_model,connection_args={"host": MILVUS_HOST,"port": MILVUS_PORT},collection_name = bookname,drop_old = True #是否删除旧的collection)return vectorDB,booknamedef load_embedding_chain_url(url=None,embedding_model=None):if embedding_model is None:llm_model,embedding_model = init_model(llm_model_name = None,embedding_model_name = None ,temperature = 0.7,max_tokens = 2000)if url:filepath = urlprint(filepath)bookname = f"temp{random.randint(0,100000)}"docs = get_documents([url])vectorDB = Milvus.from_documents(docs,embedding_model,connection_args={"host": MILVUS_HOST,"port": MILVUS_PORT},collection_name = bookname,drop_old = True #是否删除旧的collection)return vectorDB,bookname###gradioblock = gr.Blocks(css="footer {visibility: hidden}",title="文言一心助手")with block:history = ConversationBufferMemory()history_state = gr.State(history) #历史记录的状态llm_model_state = gr.State() #llm模型的状态embedding_model_state = gr.State() #embedding模型的状态milvus_books = Nonemilvus_books_state = gr.State(milvus_books) #milvus_books的状态trash = gr.State() #垃圾桶with gr.Row():#设置行with gr.Column(scale=1):with gr.Accordion("模型配置", open=False):llm_model_name = gr.Dropdown(choices=llm_model, value=llm_model[0], label="语言模型",multiselect=False,interactive=True)embedding_model_name = gr.Dropdown(choices=embedding_model, value=embedding_model[0], label="embedding模型",multiselect=False,interactive=True)temperature = gr.Slider(minimum=0.0,maximum=1.0,value=0.7,step=0.1,label="temperature",interactive=True,)max_tokens = gr.Slider(minimum=1,maximum=16384,value=1000,step=1,label="max_tokens",interactive=True,)modle_settings = gr.Button("应用")use_database = gr.Radio(["是", "否"],label="是否使用知识库",value="否")with gr.Accordion("知识库选项", open=False):with gr.Tab("上传"):file = gr.File(label='上传知识库文件',file_types=['.txt', '.md', '.docx', '.pdf','.pptx','.epub','.xlsx'])init_dataset_upload = gr.Button("应用")with gr.Tab("链接载入"):knowledge_url_box = gr.Textbox(label="url载入知识库",placeholder="请粘贴你的知识库url",show_label=True,lines=1)init_dataset_url = gr.Button("应用")use_search_engine = gr.Radio(["是", "否"],label="使用搜索引擎",value="否")with gr.Column(scale=4):chatbot = gr.Chatbot(label="文心酱")with gr.Row():message = gr.Textbox(label="在此处填写你的问题",placeholder="我有很多问题想问你......",lines=1,)with gr.Row():submit = gr.Button("发送", variant="primary")#刷新clear = gr.Button("刷新", variant="secondary")def clear_():chatbot = []history_state = ConversationBufferMemory()return "", chatbot, history_statedef user(user_message, history):return "",history + [[user_message, None]]def bot(user_message,chatbot = None,history_state = ConversationBufferMemory(),temperature = None,max_tokens = None,llm_model=None,embedding_model=None,llm_model_name = None,embedding_model_name = None,use_database = None,milvus_books_state = None,use_search_engine = None):try:user_message = chatbot[-1][0]if llm_model is None or embedding_model is None:llm_model,embedding_model = init_model(llm_model_name,embedding_model_name,temperature,max_tokens)if use_database == "否":output = init_base_chain(llm_model,history=history_state,user_question=user_message,use_search_engine=use_search_engine)else:output = init_base_embedding_chain(llm_model,embedding_model,milvus_books_state,user_question=user_message,use_search_engine=use_search_engine)except Exception as e:raise echatbot[-1][1] = ""for character in output:chatbot[-1][1] += charactertime.sleep(0.03)yield chatbot#是否使用知识库use_database.change(is_use_database, inputs=[chatbot,use_database], outputs=[chatbot])#是否使用搜索引擎use_search_engine.change(is_use_web, inputs=[chatbot,use_search_engine], outputs=[chatbot])#模型配置modle_settings.click(init_model, inputs=[llm_model_name,embedding_model_name,temperature,max_tokens], outputs=[llm_model_state,embedding_model_state]).then(apply_model_setting, inputs=[llm_model_name,embedding_model_name,chatbot], outputs=[chatbot])#知识库选项init_dataset_upload.click(pre_embeding_file,inputs=[chatbot],outputs=[chatbot]).then(load_embedding_chain_file, inputs=[file,embedding_model_state], outputs=[trash,milvus_books_state]).then(applydata_, inputs=[chatbot], outputs=[chatbot])init_dataset_url.click(pre_embeding_file,inputs=[chatbot],outputs=[chatbot]).then(load_embedding_chain_url, inputs=[knowledge_url_box,embedding_model_state], outputs=[trash,milvus_books_state]).then(applydata_, inputs=[chatbot], outputs=[chatbot])#刷新按钮clear.click(clear_, inputs=[], outputs=[message, chatbot, history_state])#send按钮submit.click(user, [message, chatbot], [message,chatbot], queue=False).then(bot, [message,chatbot,history_state,temperature,max_tokens,llm_model_state,embedding_model_state,llm_model_name,embedding_model_name,use_database,milvus_books_state,use_search_engine], [chatbot])#回车message.submit(user, [message, chatbot], [message,chatbot], queue=False).then(bot, [message,chatbot,history_state,temperature,max_tokens,llm_model_state,embedding_model_state,llm_model_name,embedding_model_name,use_database,milvus_books_state,use_search_engine], [chatbot])# 启动参数block.queue(concurrency_count=config['block']['concurrency_count']).launch(debug=config['block']['debug'],server_name=config['block']['server_name'],server_port=config['block']['server_port'],)
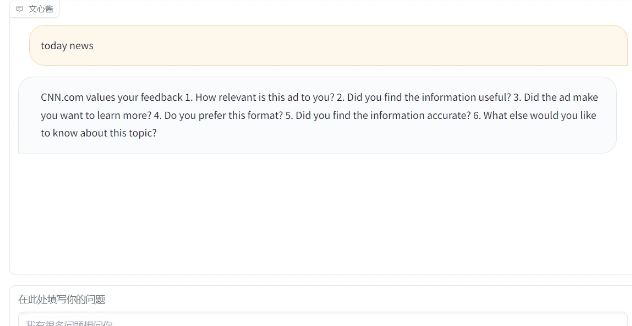

可以从我们的终端中看出我们的搜索引擎在完美运作
评论
