 模型介绍
模型介绍由Mistral AI发布的首个高质量稀疏专家混合模型 (MOE),模型由8个70亿参数专家模型组成,在多个基准测试中表现优于Llama-2-70B及GPT3.5,能够处理32K上下文,在代码生成任务中表现尤为优异。
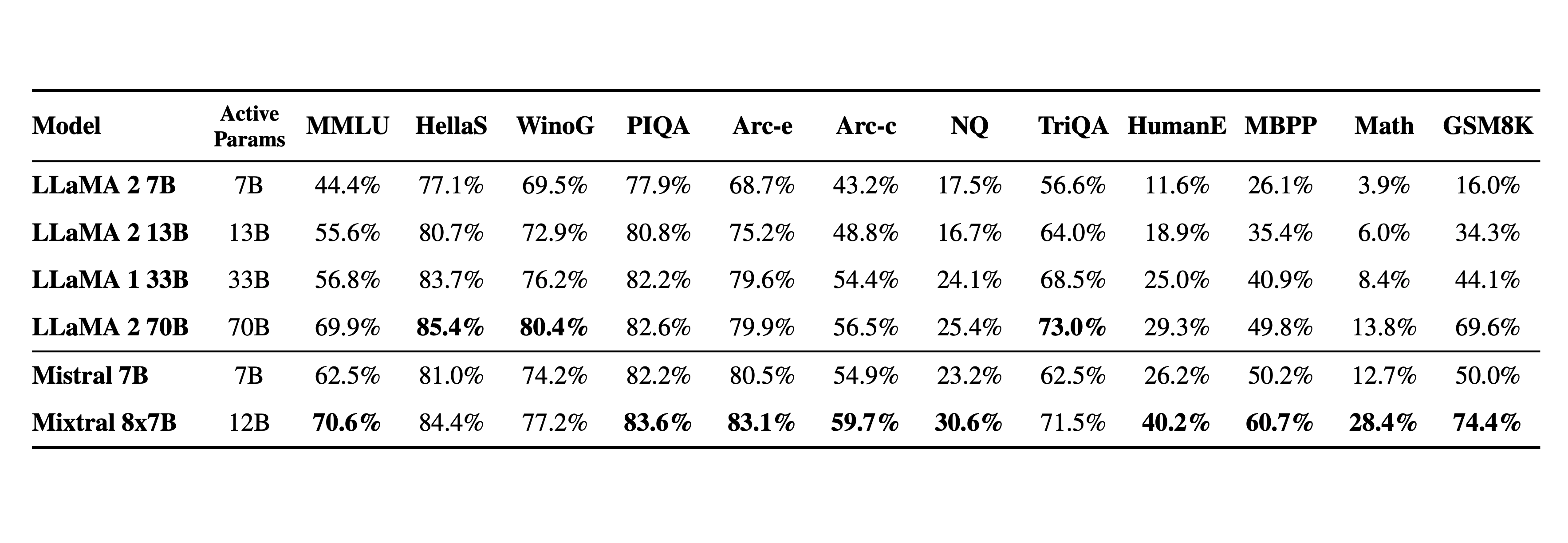
Mixtral 与 Llama 2 系列和 GPT3.5 基础模型进行比较。Mixtral 在大多数基准测试中均匹配或优于 Llama 2 70B 以及 GPT3.5。
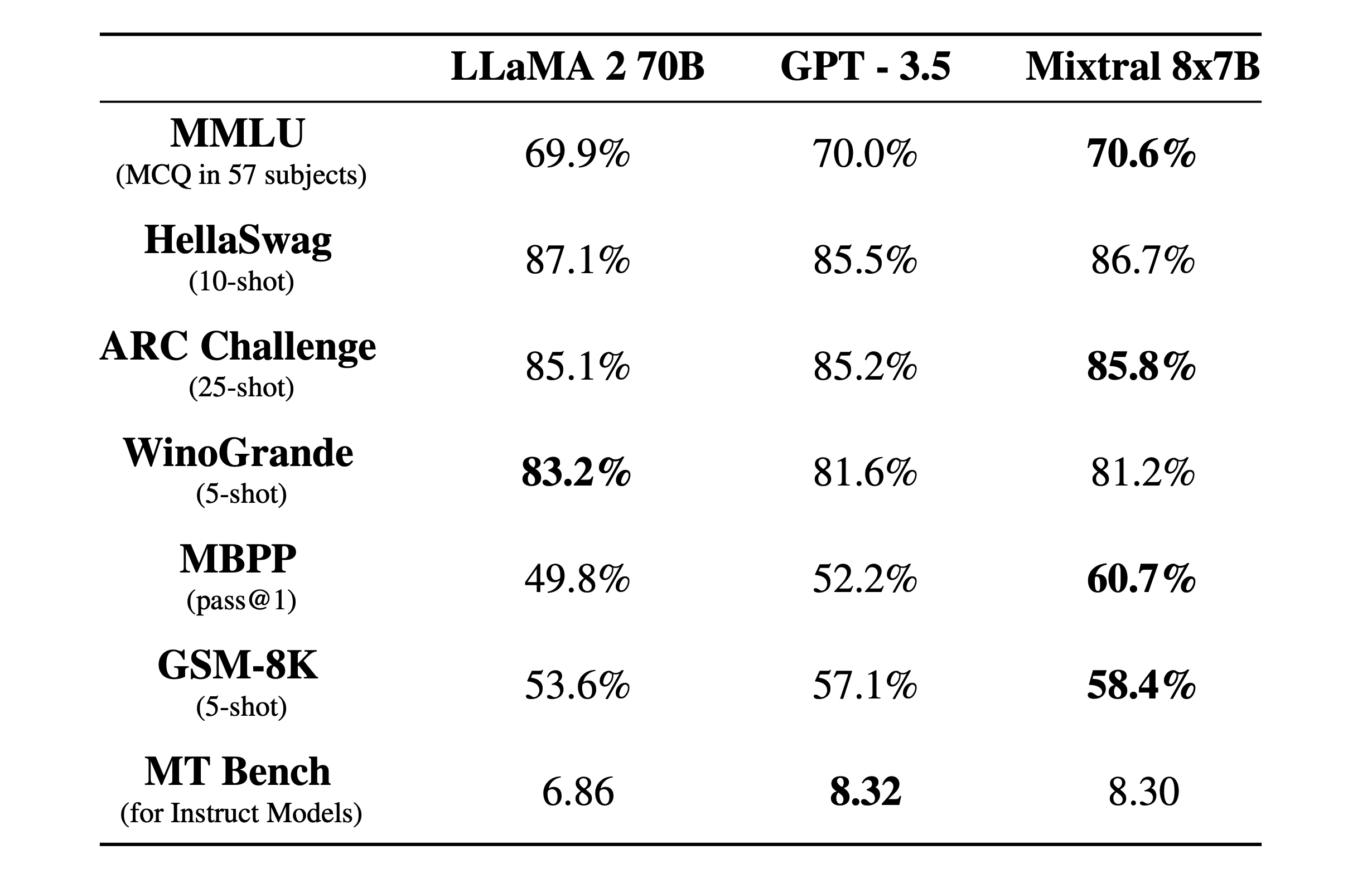
在下图中,我们衡量了质量与推理预算的权衡。与 Llama 2 型号相比,Mistral 7B 和 Mixtral 8x7B 属于高效型号系列。
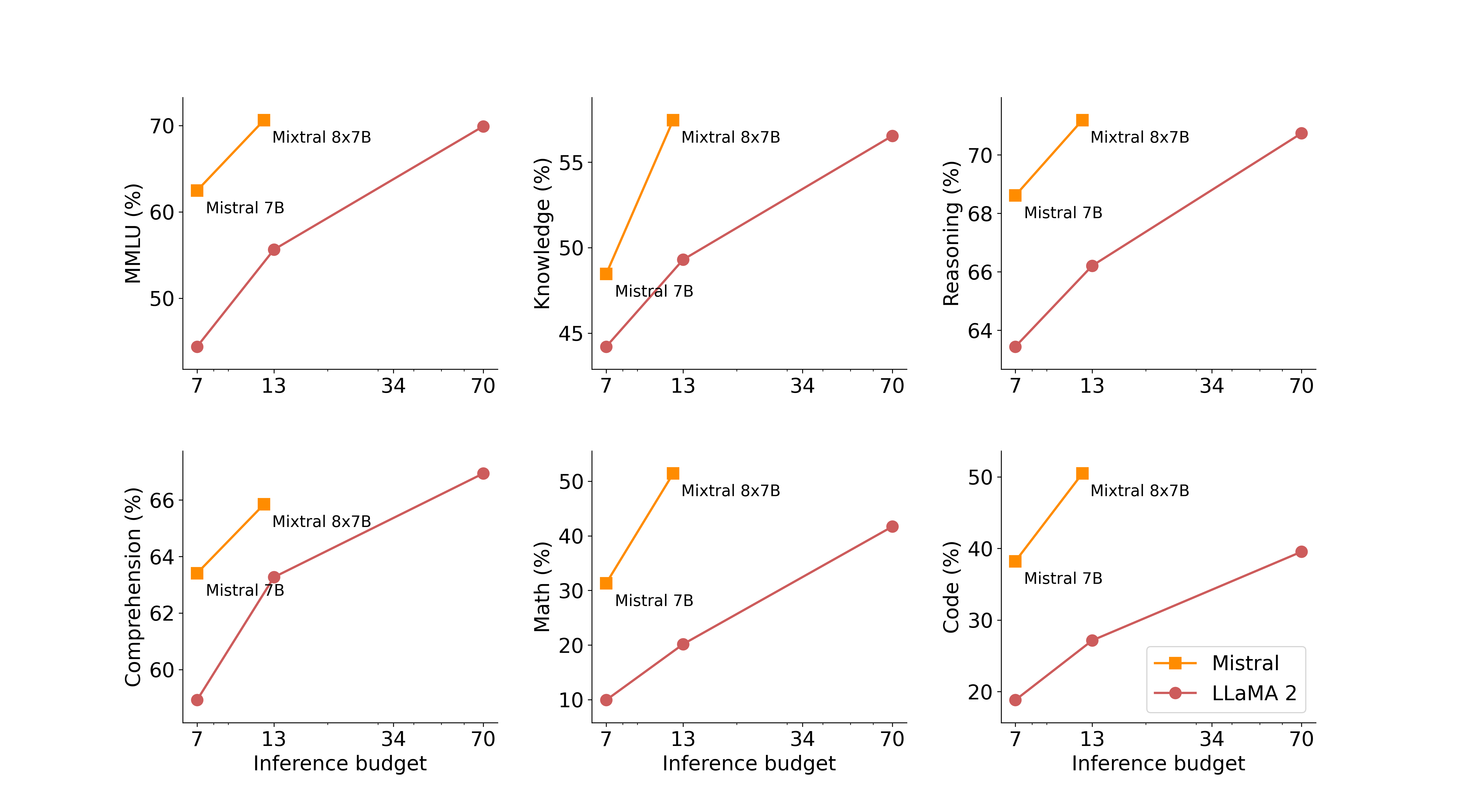
下表给出了上图的详细结果。
幻觉和偏见:为了识别可能的缺陷,通过微调/偏好建模来纠正,我们测量了BBQ/BOLD 上的基本模型性能。
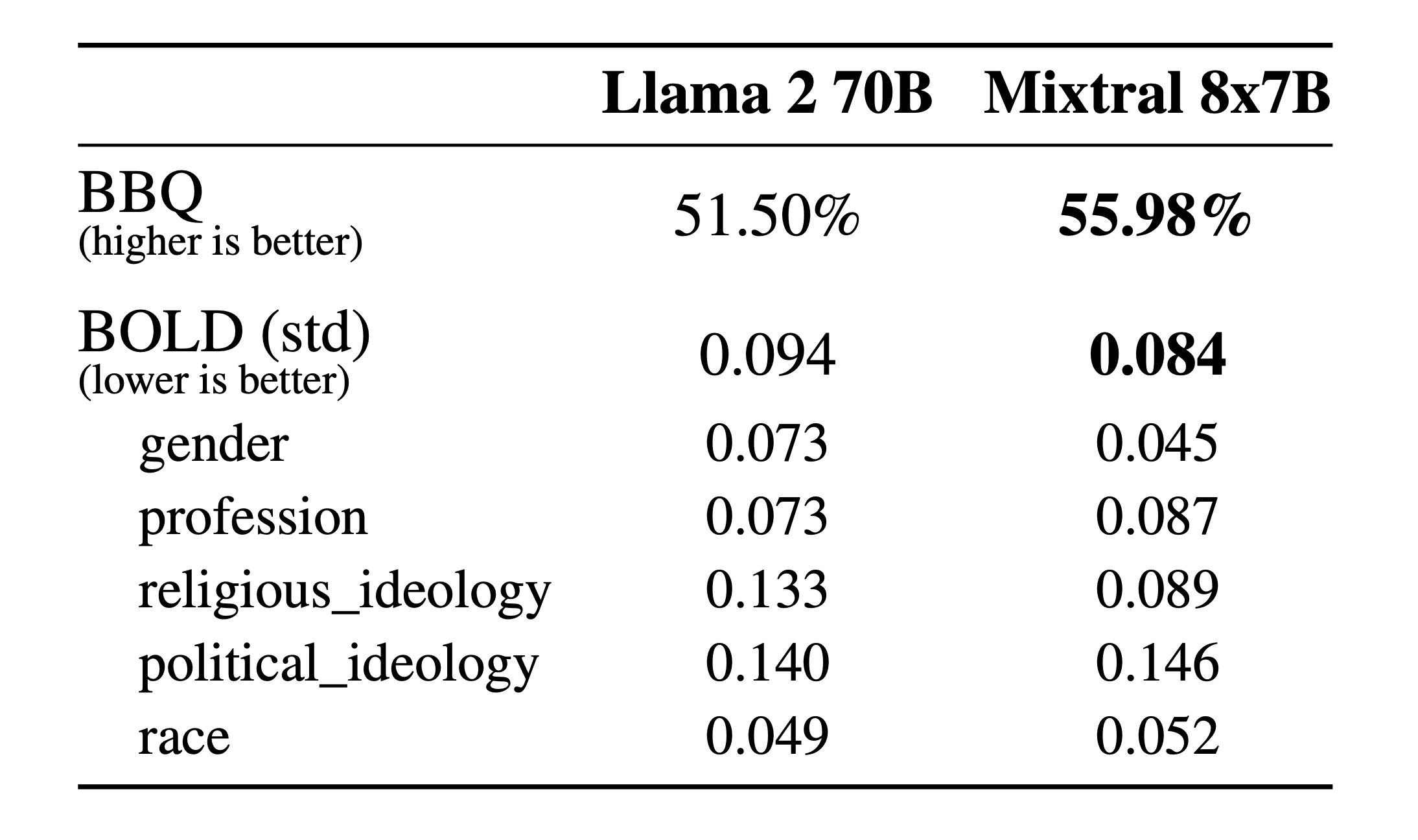
与 Llama 2 相比,Mixtral 对 BBQ 基准的偏差较小。总体而言,Mixtral 在 BOLD 上比 Llama 2 显示出更积极的情绪,每个维度内的差异相似。
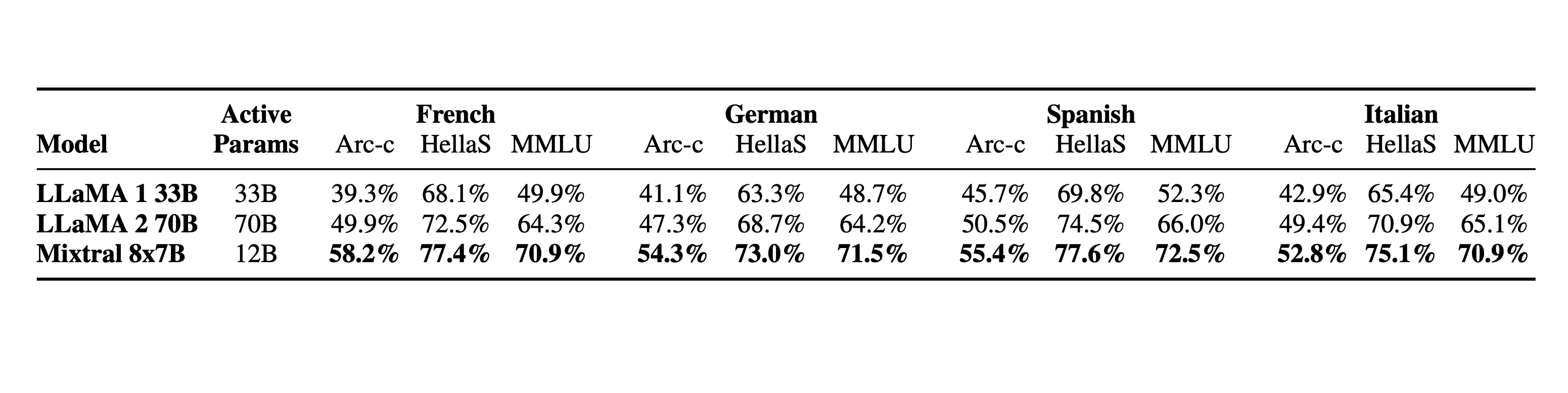
语言:Mixtral 8x7B 精通法语、德语、西班牙语、意大利语和英语。
Mixtral 是一个稀疏的专家混合网络。它是一个纯解码器模型,其中前馈块从一组 8 个不同的参数组中进行选择。在每一层,对于每个token,路由器网络选择其中的两个组(“专家”)来处理token并相加地组合它们的输出。
该技术增加了模型的参数数量,同时控制了成本和延迟,因为该模型仅使用每个token总参数集的一小部分。具体来说,Mixtral 共有 46.7B 个参数,但每个代币仅使用 12.9B 个参数。因此,它以与 12.9B 模型相同的速度和相同的成本处理输入并生成输出。
Mixtral 根据从开放网络提取的数据进行了预训练——我们同时训练专家和路由器。
Mixtral-8x7B模型来源于第三方,百度智能云千帆大模型平台不保证其合规性,请您在使用前慎重考虑,确保合法合规使用并遵守第三方的要求。 具体请查看基础模型的开源协议Apache License 2.0及模型开源页面展示信息等。 如您发现模型/数据集/文件等有任何问题,请及时联系我们处理。 由于机器学习特性,就相同的输入可能产生不同的输出结果,请您注意甄别。