产品简介
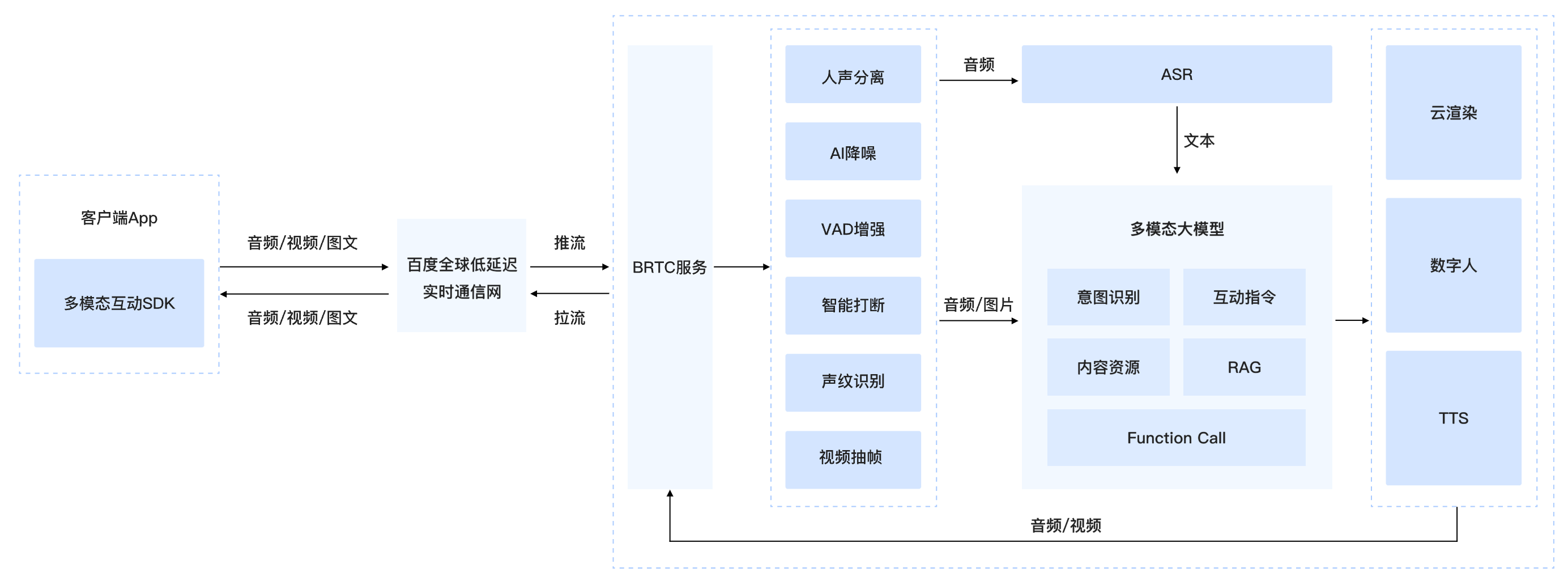
百度智能云多模态实时互动方案集语音、视觉、手势、文字、图片于一体,提供大模型语音互动、视频理解、数字人互动、任务交互等多种互动服务。端侧集成轻量化互动SDK,对音视频进行采集、处理与传输;云端深度整合全链路的ASR、LLM、TTS服务,支持FuctionCall自定义配置,通过AI降噪、人声分离、声纹提取、VAD检测、智能打断、智能抽帧等技术,对音视频进行增强处理,结合百度丰富的生态资源,提供百科、音乐、有声读物、翻译、导航等应用服务,为用户带来真人面对面的沉浸式沟通体验。
产品功能
多模态互动
输入和输出都支持多模态,支持对文本、图片、语音流、视频流等多模态内容的理解,输出也支持文本、语音、视频、等多模态内容
AI降噪
通过端侧和服务端的AI降噪算法,有效识别并消除常见的尖锐声、键盘声等非人声噪声,有效提升语音识别准确率,避免噪音误打断
智能打断
可以通过语音快速打断智能体的语音播报,也支持手动打断,实现贴近真人的自然交互体验
离线唤醒
支持定制唤醒词,通过说出预设的唤醒词离线唤醒设备,进入实时互动房间
Function Call
支持自定义配置Function Call,用户与大模型实时互动的过程中,可以说出特定指令以调用特定功能,比如【拨打电话】、【调大音量】等
意图理解
大模型根据对话内容准确理解用户意图,并可以把握对话上下文语境,理解隐含意思,给出恰当回复,顺畅与用户进行多轮交互,保证对话连贯
云渲染
支持音乐、视频、页面、文档、图片等不同类型资源在云端渲染,通过视频流传输到客户端显示,用户可以对内容进行点击、滑动等操作
字幕展示
支持将用户和大模型的语音对话信息实时转化为文字,展示在客户端
多语言
语音输入和输出均支持中英文
产品优势
超低延时互动
语音互动端到端响应延时1.4s,语音打断响应延时0.8s以内,超低延时互动,交互更流畅
丰富应用资源
打通百度丰富的生态资源,提供30+应用和资源,如百度百科、音乐、经典故事、有声读物、翻译、导航等,降低开发者对接成本
全链路音频增强
支持AI降噪、声音增益、回声消除、人声分离、声纹识别、VAD检测、智能打断,7大音频增强,云+端协同,有效提升互动体验性
开放式LUI互动框架
核心服务组件(LLM/TTS)可替换,支持Function Call自定义配置,满足满足个性化需求
全平台支持
提供开箱即用的互动SDK,只需要调用几个接口就可以快速集成多模态互动功能,支持Android、iOS、Web、小程序、Linux、RTOS等多个端
应用场景
场景概述
通过语音指令、手势控制和视觉反馈,满足百科问答、地图导航、实时翻译、图像识别、会议纪要等场景需求,提升智能眼镜的实用性和便捷性。
我们能提供
全链路实时语音互动、图片理解、视觉理解功能,提供超低延时的互动体验
打通百度丰富的应用能力,提供30+应用和资源,满足各种常见需求
支持自定义配置Function Call,通过特定语音指令触发功能,如拍照、录制、调大音量等
国内和海外共用一套SDK,降低开发成本
