【Agent护栏】新品上线全面适配OpenClaw免费试用申请!
AI安全护栏
依托前沿安全大模型,打造输入、推理、工具调用与输出全链路防护闭环。精准识别内容风险、越狱攻击、隐私泄露及智能体异常,轻量接入、实时响应,构筑大模型与 Agent 双重安全屏障。
- 标准引领深度参与TC260等相关安全标准制定
- 能力全面涵盖模型输入、输出、工具调用风险检测
- 开箱即用多种AI应用快速集成
产品矩阵
大模型安全护栏
高级攻击检测
多模态风险检测
风险代答
用户输入、模型推理环节内容安全检测,涵盖涉政、不良价值观、违法犯罪、涉黄、隐私泄露及多种高级攻击手段检测能力
Agent安全护栏
工具调用风险检测
敏感信息保护
实时阻断与强制审批
防范恶意工具调用、越权操作与异常行为风险
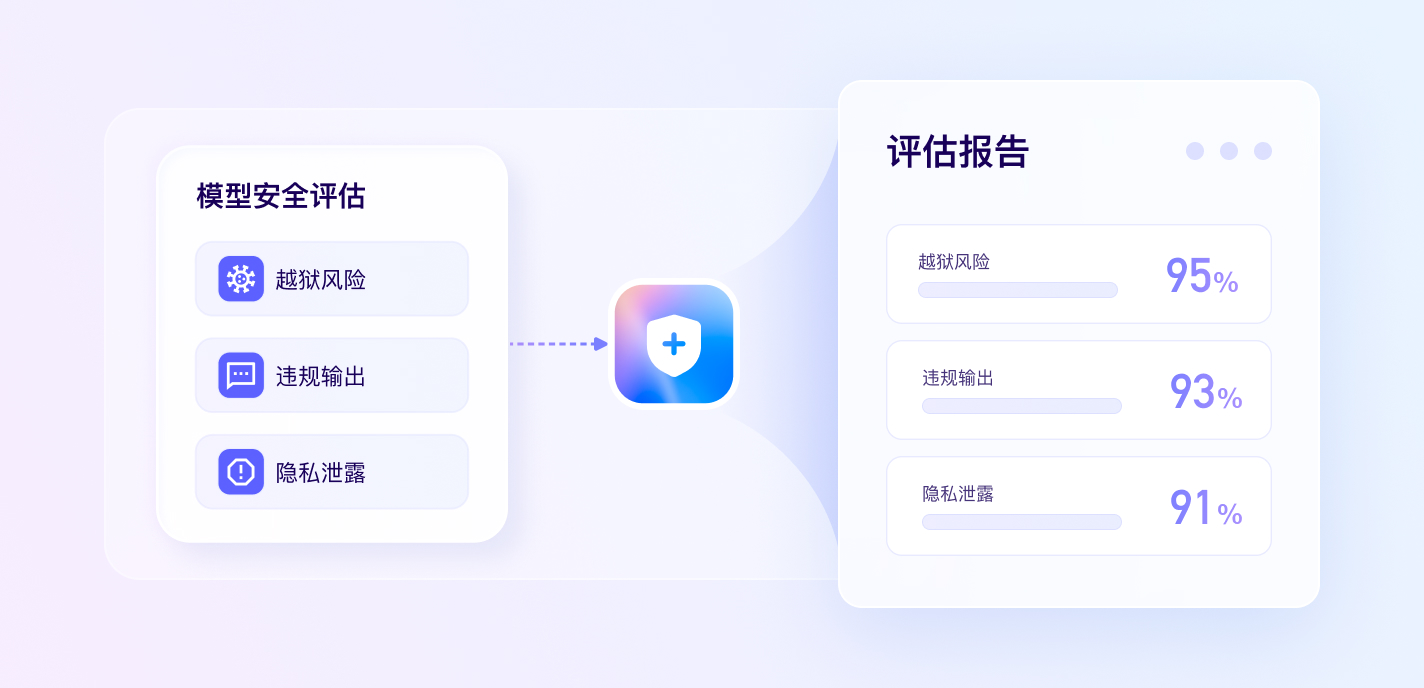
大模型安全评测
自动评测结果
丰富评测题目
舆情风险监测
构建AI场景复合风险评测体系,全面深入定位风险问题
大模型运营质检
自定义质检策略
对接护栏干预能力
质检效果远超人工
线上运营数据自动化质检与干预,极大降低人工审核工作量

产品功能
AI全链路安全闭环
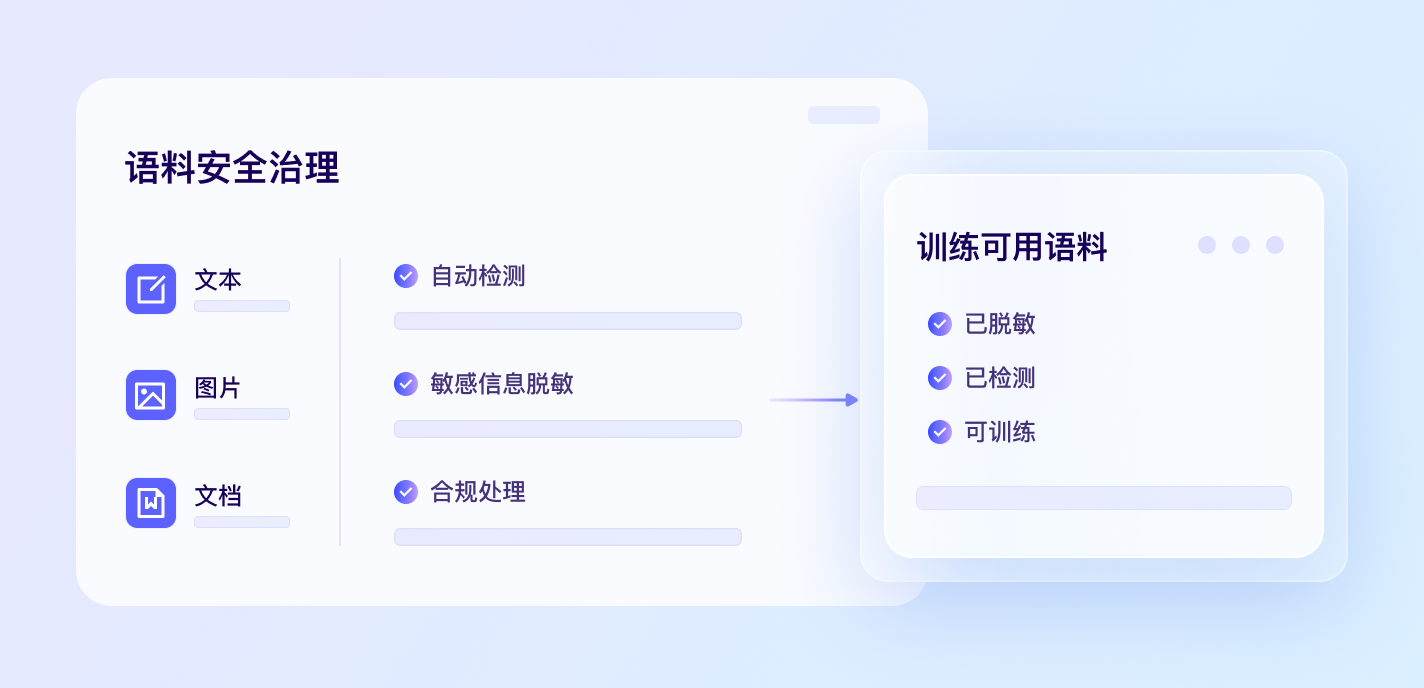
全方位AI安全防护能力,结合训练语料清洗、安全评测与运营质检系统,实现大模型与智能体全方位风险检测与防护。融合前沿视觉理解和跨模态对齐技术,实现对文本、图像等多种形式内容的全方位安全防护和处置。多模态内容审核
防范输入、输出、工具调用环节中涉及违规内容、直接/间接注入攻击等风险,保障智能体运行安全。智能体安全检测
对于恶意提示词攻击、算力消耗、提示词泄露等用户输入风险提供防护能力。高级攻击检测
产品优势
 功能完备功能完备完整的产品矩阵架构完整防护全面
功能完备功能完备完整的产品矩阵架构完整防护全面 完整的产品矩阵架构完整
完整的产品矩阵架构完整覆盖评测、防护、质检全流程。
防护全面构建AI安全全方位防护策略。

 效果优异效果优异安全效果优异审核效果优异处置流程完善
效果优异效果优异安全效果优异审核效果优异处置流程完善 安全效果优异审核效果优异
安全效果优异审核效果优异风险识别准确率、召回率效果优异。
处置流程完善根据风险自动进行拒答、代答处置。
 经验丰富经验丰富大规模落地实践经验赋能文心模型多客户落地
经验丰富经验丰富大规模落地实践经验赋能文心模型多客户落地 大规模落地实践经验赋能文心模型
大规模落地实践经验赋能文心模型技术已经搭载应用在“文心一言”及”文心千帆”中。
多客户落地助力多行业客户完成备案及线上风险防护。
 行业引领行业引领引领行业标杆行业标准参编权威认证
行业引领行业引领引领行业标杆行业标准参编权威认证 引领行业标杆行业标准参编
引领行业标杆行业标准参编深度参与 TC260 ,及信通院相关标准发布等。
权威认证中国信通院大模型安全能力评估优秀级。