- 应对挑战
- 核心防护能力
- 方案优势
- 文档与工具
- 联系我们
方案发布
应对挑战
技能供应链藏毒
智能体通过第三方Skill扩展能力,但近37%的Skill存在安全缺陷。恶意Skill继承宿主全部权限,且发布门槛极低、缺乏审查,可轻松植入后门与数据窃取载荷。
外部注入劫持行为
攻击者将隐蔽指令嵌入网页、文档等外部内容,诱使智能体执行删库、转账等高危操作。手法多样且已有在野利用,是智能体具备行动能力后的头号威胁。
权限边界模糊失控
智能体被赋予系统级超级权限却缺乏动态管控,可在授权范围内组合出超预期敏感操作。多智能体协作中单点突破还可沿信任链横向扩散,传统权限体系几乎失效。
AICG内容合规
用户输入的prompt存在违规、恶意引导等内容安全问题 大模型生成内容存在违法违规、偏见歧视、违反社会价值观、个人隐私、恐怖/极端主义等多模态内容安全问题
模型保护
大模型部署过程中可能受到对抗性攻击的威胁、以及攻击云服务器来窃取模型及其数据 部署的模型在传输和存储过程中可能被篡改 如何建立访问控制机制,确保可信用户/系统访问模型和相关资源
大模型业务运营
大模型业务运营过程中出现的账号安全问题、权益侵占等业务安权问题 用户提问行为过程中也容易出现AIGC盗爬、垃圾提问、投毒反馈、频率突破、接口攻击等问题。
核心防护能力
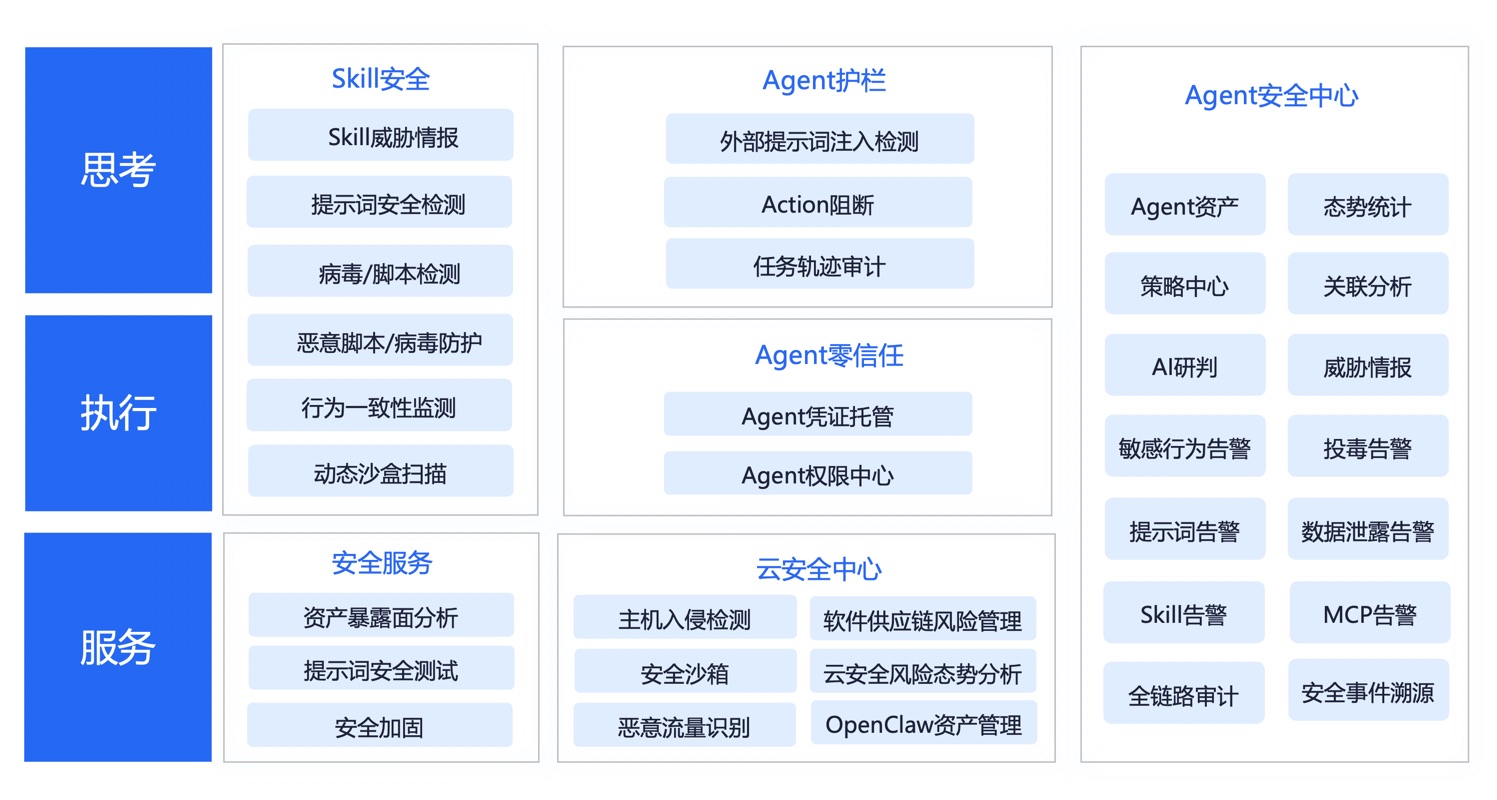
Skills安全
百度 Skills安全是⾯向 AI Agent ⽣态的技能供应链安全守卫,覆盖 Skill 从发布、安装到运⾏的完整⽣命周期。通过整合多维度安全检测能⼒,为企业和个⼈⽤⼾提供可知、可控、可追溯的 Skill 安全管理能⼒。
Agent运行时安全护栏
针对 Agent 普遍面临的外部注入、高危风险指令执行等风险,构建“感知输⼊ → ⾏动决策 → 事后审计”三层防护体系,实现:源头漏检时 Action 阻断兜底,执⾏后审计定位根因并持续反哺前两层规则优化,形成持续⾃进化的防御闭环。
Agent安全中心
Agent 安全中⼼是⾯向企业 IT 和安全团队的可视化管控平台,采集 Prompt/Task ⽇志、Action/Skill 轨迹、主机/容器/⽹络⽇志等全量安全数据,覆盖事前资产梳理、事中运⾏监测、事后追踪复盘三⼤阶段,形成⾯向 Agent 的完整监测分析闭环。
方案优势
丰富的实践经验
百度二十余年安全对抗总结,实施多个大模型安全护栏项目。
01紧贴行业需求
积极渗透AI最新应用领域,推出OpenClaw安全防护方案。
02全方位防护能力
全方位识别恶意指代、注入攻击、意识形态、敏感信息、网址安全等AIGC场景攻击方式。
03持续的攻防对抗
构建蓝军评测体系,通过攻防对抗持续提升安全防护能力。
04大模型与智能体双覆盖
同时具备针对智能体、大模型的安全防护服务,以矩阵化的产品能力打造AI安全解决方案
05