
DeepSeek-V3.2 128K 推理秒开?百度百舸开源 CP 上下文并行方案
2 天速通小米 MiMo Flash V2,vLLM-Kunlun Plugin 助力昆仑芯高效适配最新大模型
百度百舸面向百度天池超节点的大模型推理引擎优化,持续降低昆仑芯 XPU 的 token 成本
百度百舸 · AI计算平台
面向大模型训推一体化的基础设施,提供领先的AI工程加速能力,
从资源准备、模型开发、模型训练到模型部署,为AI工程全周期提供丰富特性和极致易用体验。
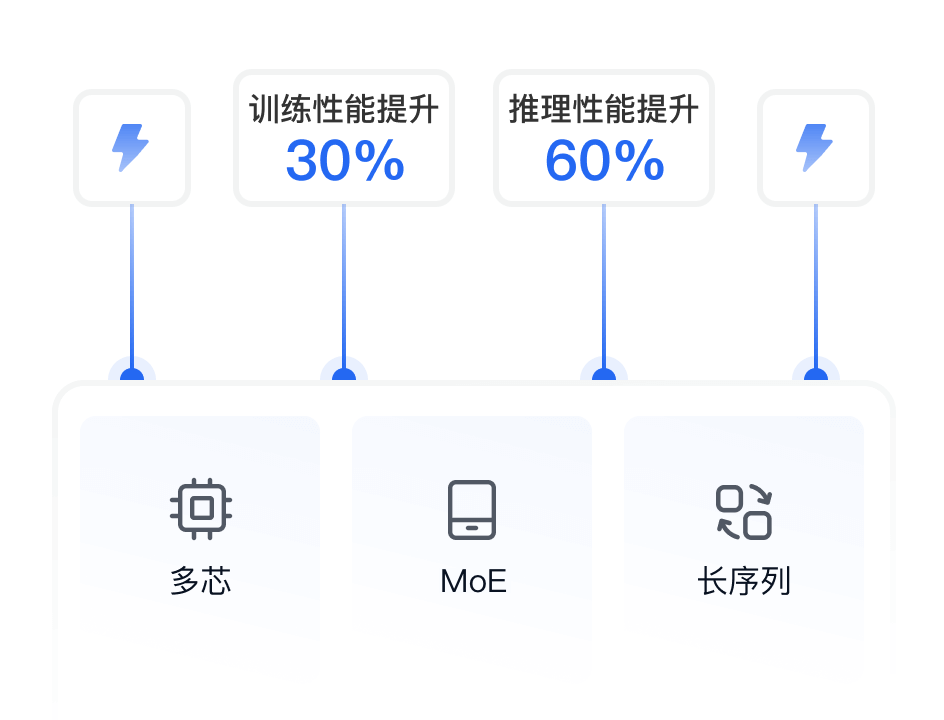
30%
模型训练
性能提升
60%
模型推理
性能提升
分钟级
万卡任务恢复
提速到1min
5%
万卡混训
性能损耗低于
99.5%
万卡集群
有效训练时长
为什么选择百度百舸AI计算平台?



全方位了解百度百舸架构
高性能的AI基础设施、高效的资源管理、全周期的AI工程平台、领先的训推加速能力
立即使用深度感受 AI 计算平台功能
 快速开始
快速开始 资源
资源 开发
开发 训练
训练 推理
推理