
消费者评论分析
简介
Hi,您好,欢迎使用百度自然语言处理应用服务。 本文档主要针对消费者评论分析的使用用户,如果您对文档内容有任何疑问,可以通过以下几种方式联系我们:
- 在百度云控制台内提交工单,咨询问题类型请选择人工智能服务;
- 如有疑问,进入AI社区交流
能力介绍
| 名称 | 能力概述 |
|---|---|
| 消费者评论分析 | 通过定制化训练的方式,帮助企业或品牌方准确提取评论中的核心观点,实现自定义评论分类,并判断消费者评论的情感极性(好评/差评),搭建数据分析系统 |
消费者评论分析的方案实现,共需要7个API接口共同配合完成: 1个业务使用接口,模型训练完成后,调用该接口,即可实现评论分析功能 2个数据管理接口,用于模型训练前的数据管理,包括评论挖掘、挖掘状态查询 2个模型训练接口,用于模型训练,包括评论分析训练、训练状态查询 2个模型部署接口,用于模型部署上线,包括模型服务部署、部署状态查询
方案实现的流程与操作步骤,如下图所示:
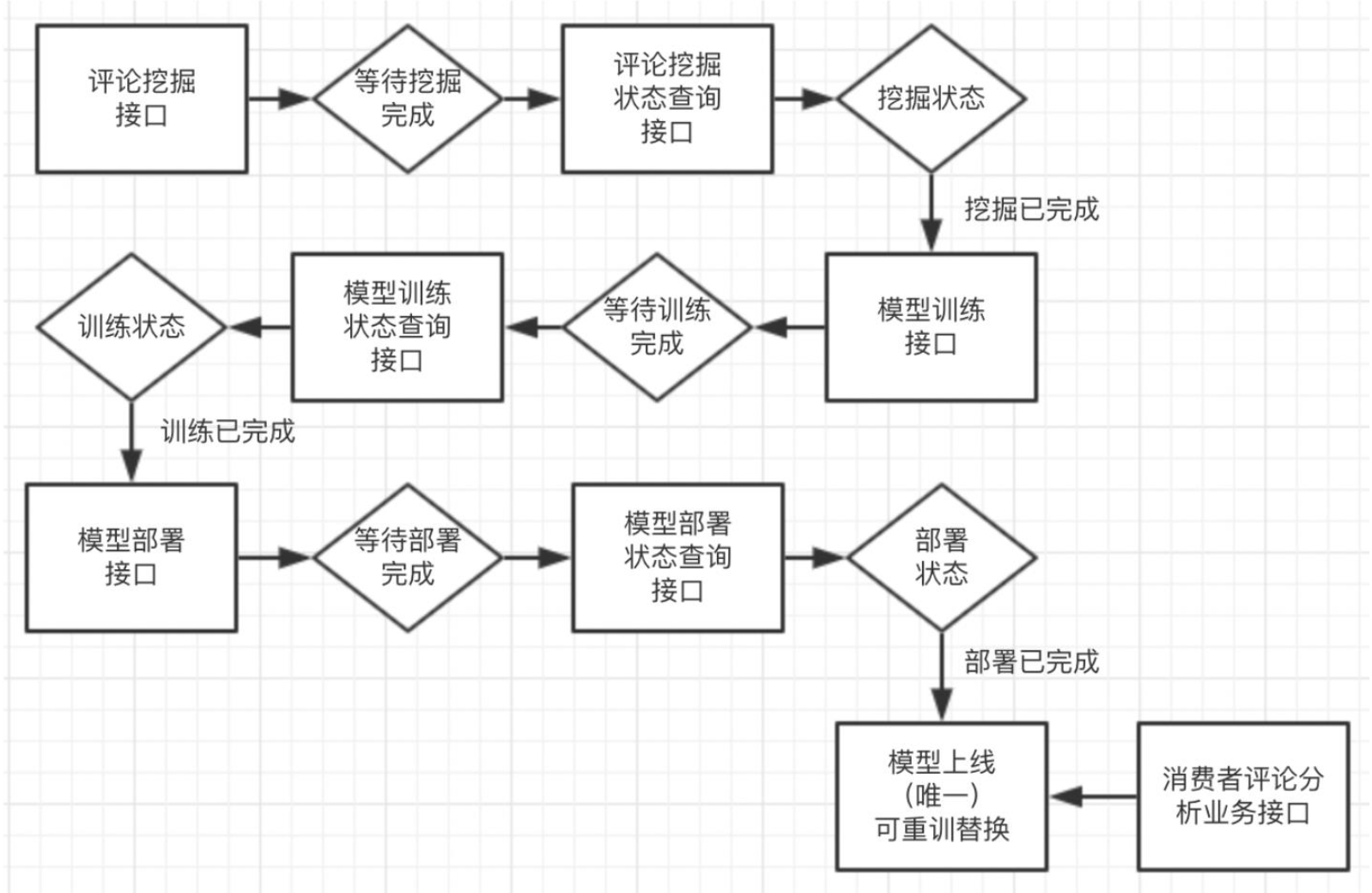
接口1:消费者评论分析业务接口
(邀测期,需发工单申请后方可使用,工单内容请填写:企业名称、APPID、业务需求,客服会第一时间回复并为您开通试用权限)
接口描述
消费者评论分析的核心应用接口,将直接对接您的应用场景 通过数据挖掘、数据标注、模型训练等技术方式,准确提取评论中的核心观点,并支持自定义评论分类,判断消费者的情感极性(好评/差评),从评论的语言描述中,帮助企业更好理解消费者的想法和感受。
请求说明
请求示例
HTTP方法: POST
请求URL: https://aip.baidubce.com/rpc/2.0/nlp/v1/ecomment
| 参数 | 值 |
|---|---|
| access_token | 通过API Key和Secret Key获取的access_token,参考“Access Token获取” |
Header如下:
| 参数 | 值 |
|---|---|
| Content-Type | application/json |
Body请求示例:
{
"text": "解决问题的能力非常差劲,晚了半个多小时,问什么时候能到,说给解决,但是解决电话又没有,也没有商家电话,只有一个统一的客服电话,什么问题都解决不了,我们只能等,外卖盒子上还写着特别快……坚决差评。",
"type": 4
}请求格式
POST方式调用
注意:要求使用JSON格式的结构体来描述一个请求的具体内容。
body整体文本内容可以支持GBK和UTF-8两种格式的编码。
1、GBK支持:默认按GBK进行编码,输入内容为GBK编码,输出内容为GBK编码,否则会接口报错编码错误
2、UTF-8支持:若文本需要使用UTF-8编码,请在url参数中添加charset=UTF-8 (大小写敏感) 例如https://aip.baidubce.com/rpc/2.0/nlp/v1/lexer?charset=UTF-8&access_token=24.f9ba9c5241b67688bb4adbed8bc91dec.2592000.1485570332.282335-8574074
请求参数
| 参数 | 是否必选 | 类型 | 描述 |
|---|---|---|---|
| text | 必选 | string | 评论内容,最大10240字节 |
| type | 必选 | number | 不同评论类型,1-15 |
其中type包含15个类别,具体取值说明如下:
| type参数 | 说明 | 实例 |
|---|---|---|
| 1 | 酒店 | 『酒店设备齐全、干净卫生』->『酒店设备齐全』、『干净卫生』 |
| 2 | KTV | 『环境一般般把,音响设备也一般,隔音太差』->『环境一般』、『音响设备一般』、『隔音差』 |
| 3 | 丽人 | 『手法专业,重要的是效果很棒』->『手法专业』、『效果不错』 |
| 4 | 美食餐饮 | 『但是味道太好啦,舍不得剩下』->『味道不错』 |
| 5 | 旅游 | 『景区交通方便,是不错的旅游景点』->『交通方便』、『旅游景点不错』 |
| 6 | 健康 | 『环境很棒,技师服务热情』->『环境不错』、『服务热情』 |
| 7 | 教育 | 『教学质量不错,老师很有经验』->『教学质量不错』、『老师有经验』 |
| 8 | 商业 | 『该公司服务好,收费低,效率高』->『服务好』、『收费低』、『效率高』 |
| 9 | 房产 | 『该房周围设施齐全、出行十分方便』->『设施齐全』、『出行方便』 |
| 10 | 汽车 | 『路宝的优点就是安全性能高、空间大』->『安全性能高』、『空间大』 |
| 11 | 生活 | 『速度挺快、服务态度也不错』->『速度快』、『服务好』 |
| 12 | 购物 | 『他家的东西还是挺贵的』->『消费贵』 |
| 13 | 3C | 『手机待机时间长』->『待机时间长』 |
| 14 | 微博 | 『颜值高,身材好』->『颜值高』、『身材好』 |
| 15 | 其他 | 如评论内容非以上14个类型,则建议选此类 |
返回格式
JSON格式
默认返回内容为GBK编码
若用户指定输入为UTF-8编码(通过指定charset参数),则返回内容为UTF-8编码
返回参数
| 参数 | 类型 | 描述 |
|---|---|---|
| log_id | uint64 | 请求唯一标识码 |
| overall_sentiment | string | 整段评论的情感极性,0负向,1中性,2正向 |
| pos_prob | string | 正面评论的概率 |
| neg_prob | string | 负面评论的概率 |
| items | string | 评论观点抽取结果列表 |
| +prop | string | 观点属性词 |
| +adj | string | 观点描述词 |
| +abstract | string | 观点对应的短句 |
| +begin_pos | string | 观点句的起始位置 |
| +end_pos | string | 观点句的结束位置 |
| +sentiment | string | 观点对应的情感极性,0负向,1中性,2正向 |
| +clf_tag | string | 短句中观点的类别,未标注数据训练,则为空 |
| +clf_score | string | 观点类别的置信度 |
返回示例
{
"neg_prob": 0.999998,
"log_id": 3583691685022491472,
"pos_prob": 0.0000018893,
"items": [
{
"clf_tag": "其他",
"sentiment": 0,
"abstract": "也没有商家电话",
"clf_score": 1,
"prop": "商家差",
"begin_pos": 0,
"end_pos": 14,
"adj": ""
},
{
"clf_tag": "其他",
"sentiment": 0,
"abstract": "只有一个统一的客服电话",
"clf_score": 1,
"prop": "客服差",
"begin_pos": 0,
"end_pos": 22,
"adj": ""
}
],
"overall_sentiment": 0
}接口2:消费者评论分析-评论挖掘接口
(邀测期,需发工单申请后方可使用,工单内容请填写:企业名称、APPID、业务需求,客服会第一时间回复并为您开通试用权限)
接口描述
消费者评论分析的定制化接口,帮助您整理收集模型训练数据 通过此接口上传原始评论数据,系统会自动启动数据挖掘任务,等待参考时间约10分钟左右(等待时间与数据量大小正相关),完成评论挖掘的基础工作。
请求说明
请求示例
HTTP方法: POST
-请求URL: https://aip.baidubce.com/rpc/2.0/nlp/v1/ecomment/mining
| 参数 | 值 |
|---|---|
| access_token | 通过API Key和Secret Key获取的access_token,参考“Access Token获取” |
Header如下:
| 参数 | 值 |
|---|---|
| Content-Type | application/json |
Body请求示例:
{
"raw_data": "https://xxx.xxx/xxx.txt"
}请求格式
POST方式调用
注意:要求使用JSON格式的结构体来描述一个请求的具体内容。
body整体文本内容可以支持GBK和UTF-8两种格式的编码。
1、GBK支持:默认按GBK进行编码,输入内容为GBK编码,输出内容为GBK编码,否则会接口报错编码错误
2、UTF-8支持:若文本需要使用UTF-8编码,请在url参数中添加charset=UTF-8 (大小写敏感) 例如https://aip.baidubce.com/rpc/2.0/nlp/v1/lexer?charset=UTF-8&access_token=24.f9ba9c5241b67688bb4adbed8bc91dec.2592000.1485570332.282335-8574074
请求参数
| 参数 | 类型 | 描述 |
|---|---|---|
| raw_data | string | 原始评论数据的http链接 |
http链接中的文件内容与格式要求:
1、格式:UTF-8编码txt文件
2、内容:每行一条原始评论
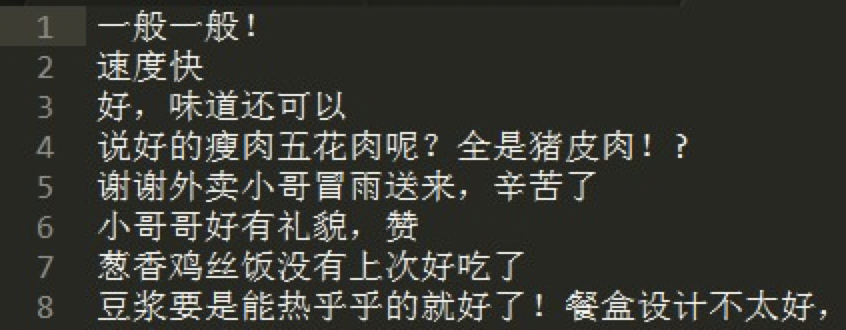
返回格式
JSON格式
默认返回内容为GBK编码
若用户指定输入为UTF-8编码(通过指定charset参数),则返回内容为UTF-8编码
返回说明
返回参数
| 参数 | 说明 | 描述 |
|---|---|---|
| log_id | number | 请求唯一标识码 |
| model_id | number | 评论挖掘模型ID,用于后续评论挖掘结果查询 |
返回示例
{
"log_id": 8111004055035146270,
"model_id": 1001
}接口3:消费者评论分析-查询评论挖掘接口
(邀测期,需发工单申请后方可使用,工单内容请填写:企业名称、APPID、业务需求,客服会第一时间回复并为您开通试用权限)
接口描述
消费者评论分析的定制化辅助接口,帮助您查询状态 查询评论挖掘的状态,是否完成,如果挖掘完成,可进入到下一步的模型训练。
请求说明
请求示例
HTTP方法: POST
请求URL: https://aip.baidubce.com/rpc/2.0/nlp/v1/ecomment/query_mining
| 参数 | 值 |
|---|---|
| access_token | 通过API Key和Secret Key获取的access_token,参考“Access Token获取” |
Header如下:
| 参数 | 值 |
|---|---|
| Content-Type | application/json |
Body请求示例:
{
"model_id": 1001
}请求格式
POST方式调用
注意:要求使用JSON格式的结构体来描述一个请求的具体内容。
body整体文本内容可以支持GBK和UTF-8两种格式的编码。
1、GBK支持:默认按GBK进行编码,输入内容为GBK编码,输出内容为GBK编码,否则会接口报错编码错误
2、UTF-8支持:若文本需要使用UTF-8编码,请在url参数中添加charset=UTF-8 (大小写敏感) 例如https://aip.baidubce.com/rpc/2.0/nlp/v1/lexer?charset=UTF-8&access_token=24.f9ba9c5241b67688bb4adbed8bc91dec.2592000.1485570332.282335-8574074
请求参数
| 参数 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
| model_id | number | 是 | 待查询状态的评论挖掘模型ID |
返回格式
JSON格式
默认返回内容为GBK编码
若用户指定输入为UTF-8编码(通过指定charset参数),则返回内容为UTF-8编码
返回说明
返回参数
| 参数 | 说明 | 描述 |
|---|---|---|
| log_id | number | 请求唯一标识码 |
| status | number | 评论挖掘状态,0: 进行中,1:成功,2:失败 |
| temporary_model_addr | string | 评论挖掘成功时返回,评论挖掘结果链接,30分钟内失效,请及时获取 |
返回示例
{
"status": 1,
"log_id": 5763838446742083280
"temporary_model_addr": "http://xxx"
}接口4:消费者评论分析-评论分析训练接口
(邀测期,需发工单申请后方可使用,工单内容请填写:企业名称、APPID、业务需求,客服会第一时间回复并为您开通试用权限)
接口描述
消费者评论分析的定制化接口,帮助您进行模型定制、效果调优 选择用于模型训练的数据,进行观点抽取、观点分类的模型优化训练,一般模型训练的参考等待时间约为30分钟,请您耐心等待,也可通过查询接口查询当前模型的训练状态。 用于模型训练的数据,分为两部分: 1、情感搭配词典:人工修正系统挖掘出的词典,将系统挖掘错误的词典更改为预期结果,修正与确认越精准,模型训练的观点抽取效果越好。 2、维度分类词典:人工标注分类需求,将抽取出的维度词或主体词与需求的分类类别进行一一对应标注,一般建议标注至少前20%,分类数据标注越多,模型训练的分类效果越好。
请求说明
请求示例
HTTP方法: POST
请求URL: https://aip.baidubce.com/rpc/2.0/nlp/v1/ecomment/train
| 参数 | 值 |
|---|---|
| access_token | 通过API Key和Secret Key获取的access_token,参考“Access Token获取” |
Header如下:
| 参数 | 值 |
|---|---|
| Content-Type | application/json |
Body请求示例:
{
"model_id": 1001
}请求格式
POST方式调用
注意:要求使用JSON格式的结构体来描述一个请求的具体内容。
body整体文本内容可以支持GBK和UTF-8两种格式的编码。
1、GBK支持:默认按GBK进行编码,输入内容为GBK编码,输出内容为GBK编码,否则会接口报错编码错误
2、UTF-8支持:若文本需要使用UTF-8编码,请在url参数中添加charset=UTF-8 (大小写敏感) 例如https://aip.baidubce.com/rpc/2.0/nlp/v1/lexer?charset=UTF-8&access_token=24.f9ba9c5241b67688bb4adbed8bc91dec.2592000.1485570332.282335-8574074
请求参数
| 参数 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
| raw_data | string | 是 | 原始数据的http链接 |
| trigram_data | string | 是 | 情感搭配词典的http链接(实现抽取需求) |
| prop_data | string | 是 | 维度分类词典的http链接(实现分类需求) |
| type | number | 是 | 不同评论类型,1-15 |
http链接中的文件内容与格式要求:
1、格式:UTF-8编码txt文件
2、内容:
- 情感搭配词典:三列,\t分隔,维度词、评价词、情感极性
- 维度分类词典:二列,\t分隔,维度、维度对应的分类类别
返回参数
| 参数 | 说明 | 描述 |
|---|---|---|
| log_id | number | 请求唯一标识码 |
| model_id | number | 评论分析模型ID,用于后续评论分析模型部署 |
{
"log_id": 8111004055035146270,
"model_id": 1002
}接口5:消费者评论分析-查询评论分析训练接口
(邀测期,需发工单申请后方可使用,工单内容请填写:企业名称、APPID、业务需求,客服会第一时间回复并为您开通试用权限)
接口描述
消费者评论分析的定制化辅助接口,帮助您查询状态 查询模型训练的状态是否完成,如果模型训练完成,可进入到下一步的模型部署步骤。
请求说明
请求示例
HTTP方法: POST
-请求URL: https://aip.baidubce.com/rpc/2.0/nlp/v1/ecomment/query_train
| 参数 | 值 |
|---|---|
| access_token | 通过API Key和Secret Key获取的access_token,参考“Access Token获取” |
Header如下:
| 参数 | 值 |
|---|---|
| Content-Type | application/json |
Body请求示例:
{
"model_id": 1001
}请求格式
POST方式调用
注意:要求使用JSON格式的结构体来描述一个请求的具体内容。
body整体文本内容可以支持GBK和UTF-8两种格式的编码。
1、GBK支持:默认按GBK进行编码,输入内容为GBK编码,输出内容为GBK编码,否则会接口报错编码错误
2、UTF-8支持:若文本需要使用UTF-8编码,请在url参数中添加charset=UTF-8 (大小写敏感) 例如https://aip.baidubce.com/rpc/2.0/nlp/v1/lexer?charset=UTF-8&access_token=24.f9ba9c5241b67688bb4adbed8bc91dec.2592000.1485570332.282335-8574074
请求参数
| 参数 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
| model_id | string | 是 | 待查询训练状态的ID |
返回参数
| 参数 | 说明 | 描述 |
|---|---|---|
| log_id | number | 请求唯一标识码 |
| status | number | 评论分析状态,0: 进行中,1:成功,2:失败 |
{
"log_id": 8111004055035146270,
"status": 1
}接口6:消费者评论分析-模型服务部署接口
(邀测期,需发工单申请后方可使用,工单内容请填写:企业名称、APPID、业务需求,客服会第一时间回复并为您开通试用权限)
接口描述
如果您的模型已训练完成,可以用于上线测试,则可通过该接口发起模型部署。一般模型部署的参考等待时间约为30分钟,请您耐心等待,也可通过查询接口查询当前部署状态。
请求说明
请求示例
HTTP方法: POST
请求URL: https://aip.baidubce.com/rpc/2.0/nlp/v1/ecomment/deploy
| 参数 | 值 |
|---|---|
| access_token | 通过API Key和Secret Key获取的access_token,参考“Access Token获取” |
Header如下:
| 参数 | 值 |
|---|---|
| Content-Type | application/json |
Body请求示例:
{
"model_id": 1001
}请求格式
POST方式调用
注意:要求使用JSON格式的结构体来描述一个请求的具体内容。
body整体文本内容可以支持GBK和UTF-8两种格式的编码。
1、GBK支持:默认按GBK进行编码,输入内容为GBK编码,输出内容为GBK编码,否则会接口报错编码错误
2、UTF-8支持:若文本需要使用UTF-8编码,请在url参数中添加charset=UTF-8 (大小写敏感) 例如https://aip.baidubce.com/rpc/2.0/nlp/v1/lexer?charset=UTF-8&access_token=24.f9ba9c5241b67688bb4adbed8bc91dec.2592000.1485570332.282335-8574074
请求参数
| 参数 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
| model_id | string | 是 | 待发起部署的模型ID |
返回参数
| 参数 | 说明 | 描述 |
|---|---|---|
| log_id | number | 请求唯一标识码 |
{
"log_id": 8111004055035146270
}接口7:消费者评论分析-查询模型服务状态接口
(邀测期,需发工单申请后方可使用,工单内容请填写:企业名称、APPID、业务需求,客服会第一时间回复并为您开通试用权限)
接口描述
发起模型部署后,可用该接口查询模型部署的状态,如果模型顺利部署成功,则可以使用业务接口进行实际调用,满足消费者评论分析的需求。
请求说明
请求示例
HTTP方法: POST
请求URL: https://aip.baidubce.com/rpc/2.0/nlp/v1/ecomment/query_deploy
| 参数 | 值 |
|---|---|
| access_token | 通过API Key和Secret Key获取的access_token,参考“Access Token获取” |
Header如下:
| 参数 | 值 |
|---|---|
| Content-Type | application/json |
Body请求示例:
{
"model_id": 1001
}请求格式
POST方式调用
注意:要求使用JSON格式的结构体来描述一个请求的具体内容。
body整体文本内容可以支持GBK和UTF-8两种格式的编码。
1、GBK支持:默认按GBK进行编码,输入内容为GBK编码,输出内容为GBK编码,否则会接口报错编码错误
2、UTF-8支持:若文本需要使用UTF-8编码,请在url参数中添加charset=UTF-8 (大小写敏感) 例如https://aip.baidubce.com/rpc/2.0/nlp/v1/lexer?charset=UTF-8&access_token=24.f9ba9c5241b67688bb4adbed8bc91dec.2592000.1485570332.282335-8574074
请求参数
| 参数 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
| model_id | string | 是 | 待查询部署状态的模型ID |
返回参数
| 参数 | 说明 | 描述 |
|---|---|---|
| log_id | number | 请求唯一标识码 |
| service_status | number | 模型服务状态,0: 服务未在线1:服务已上线 |
{
"log_id": 8111004055035146270
"service_status": 1
}接口错误码说明
| 错误码 | 错误信息 | 详情与建议 |
|---|---|---|
| 1 | Unknown error | 服务器内部错误,请再次请求,如果持续出现此类错误,请通过QQ群(224994340)或工单联系技术支持团队解决 |
| 2 | Service temporarily unavailable | 服务暂不可用,请再次请求,如果持续出现此类错误,请通过QQ群(224994340)或工单联系技术支持团队解决 |
| 3 | Unsupported openapi method | 调用的API不存在,请检查接口地址是否输入正确 |
| 4 | Open apirequest limit reached | 集群超限额,请通过QQ群(224994340)或工单联系技术支持团队 |
| 6 | No permission to access data | 无权限访问,请检查创建的APP应用是否有该接口的使用权限(1、API列表页是否可见、2、应用详情的接口是否勾选) |
| 17 | Open api daily request limit reached | 每天请求量超限额,请您严格控制日调用量,调用量需<=该接口的日调用量限制,若有更高调用量需求,请前往产品页面进行购买或通过QQ群(632426386)进行咨询 |
| 18 | Open api qps request limit reached | QPS超限额,请您严格控制处理并发量,调用并发需<=该接口的QPS限制,若有更高QPS需求,请前往产品页面进行购买或通过QQ群(632426386)进行咨询 |
| 19 | Open api total request limit reached | 请求总量超限额 |
| 100 | Invalid parameter | 输入中包含了无效或错误参数,请检查代码 |
| 110 | Access token invalid or no longer valid | Access Token失效,请进行更换 |
| 111 | Access token expired | Access token过期,Access Token的有效期为30天,请在到期前进行更换 |
| 282000 | internal error | 服务器内部错误,请再次请求,如果持续出现此类错误,请通过QQ群(632426386)或工单联系技术支持团队 |
| 282002 | input encodingerror | 编码错误,接口默认支持的是GBK编码,若需要输入的文本为UTF-8编码,请在url上添加参数charset=UTF-8 |
| 282004 | invalid parameter(s) | 请求中包含非法参数,请检查后重新尝试 |
| 282008 | unsupported charset:{字符编码名称} | 仅支持GBK和UTF-8,其余为不支持的字符编码,请检查后重新尝试 |
| 282011 | API not customized | 定制化接口未使用数据进行训练,或者训练后未生效该接口,建议检查定制化是否完成数据训练以及是否已生效该接口 |
| 282130 | no result | 当前查询无结果返回,请检查原始评论中是否含有核心观点,也可能是机器召回不足导致观点无法被识别到导致,如需优化,请工单反馈 |
| 282131 | input text too long | 输入长度超限,请参照接口文档说明,检查输入文本的长度,并进行严格控制,如需求无法满足请工单联系客服 |
| 282133 | param {参数名} not exist | 接口参数缺失,请检查输入参数是否优遗漏,补充参数并再次尝试 |
| 282134 | input empty | 输入为空,请检查输入内容,输入的内容避免为空 |
| 282300 | word error | 算法词典暂未收录该word,可联系客服做算法版本的升级以进行支持,相关badcase和需求可以提交工单进行咨询 |
| 282301 | word_1 error | word_1提交的词汇暂未收录,无法比对相似度,可联系客服做算法版本升级进行支持,相关badcase和需求可以提交工单进行咨询 |
| 282302 | word_2 error | word_2提交的词汇暂未收录,无法比对相似度,可联系客服做算法版本升级进行支持,相关badcase和需求可以提交工单进行咨询 |
| 282303 | word_1&word_2 error | word_1和word_2暂未收录,无法比对相似度,可联系客服做算法版本升级进行支持,相关badcase和需求可以提交工单进行咨询 |
| 282355 | storage space full | 达到存储数量上限,请检查已经创建的实体库或实体名单数量 |
| 282501 | input text length invalid | 单个实体的字符串长度超限,请控制长度限制为64个字符内 |